面壁动态面壁智能牵手加速进化机器人,打造端侧模型与具身机器人融合先驱2024 世界机器人大会期间,面壁智能联手加速进化机器人(Booster Robotics),打造出完整“具身智能”的先驱方案,业界首个高效端侧模运行在人形机器人的演示,理解、推理、并与物理世界互动的智能系统,这激动人心的未来场景,已拉开帷幕!
面壁动态星标破万!小钢炮2.6登顶GitHub,Hugging Face TOP3, 燃爆开源社区!MiniCPM-V 2.6 一经发布,火箭登顶全球著名开源社区 GitHub 与 HuggingFace 趋势榜 Top 3。 至此,面壁小钢炮 MiniCPM-V系列,GitHub 星标破万! 小钢炮MiniCPM系列自今年2月1日面世以来,累计下载量已超百万!
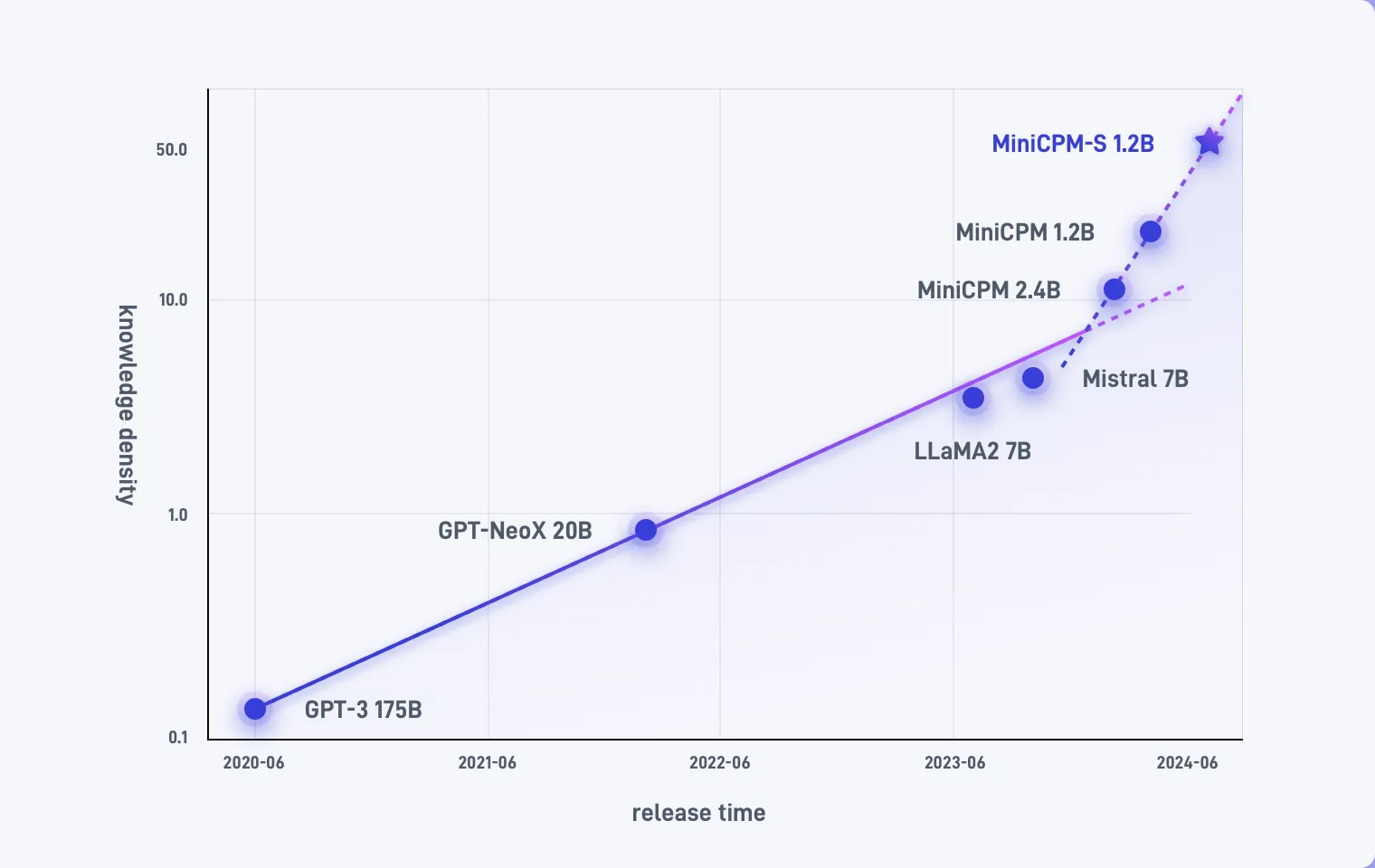
面壁动态2024世界机器人大会,刘知远最新演讲:大模型、知识密度定律与端侧智能8 月 21 日下午,2024 世界机器人大会 (WRC)「大模型技术赋能机器人产业新范式论坛」正式举行,面壁智能联合创始人、首席科学家刘知远受邀出席并发表《大模型、知识密度定律与端侧智能》主题演讲。
面壁动态面壁智能受邀出席《财富》人工智能主题大会近日,面壁智能作为中国大模型企业代表,受邀出席正在新加坡举办的 2024《财富》(Fortune)人工智能主题大会。
面壁动态牵手华为,打造“高效”大模型的基础创新生态2024 世界人工智能大会(WAIC)期间,面壁智能联合创始人、CEO李大海和华为计算产品线总裁张熙伟共同出席了双方合作交流研讨会,并正式签署昇腾原生开发合作备忘录。
面壁动态GPT-4V级端侧小钢炮, 8B参数,8G显存,4070轻松推理!时隔 1 个月,小钢炮 MiniCPM 系列上新,带来 MiniCPM-Llama3-V 2.5 ,最强端侧多模态模型。通过一系列自研技术,小钢炮系列开创的高清图像识别(1344 * 1344分辨率)、强大 OCR 能力等,仍得到延续。
面壁动态超强端侧多模态大模型MiniCPM-V 2.0: 具备领先OCR和理解能力我们推出 MiniCPM 系列的最新多模态版本 MiniCPM-V 2.0。该模型基于 MiniCPM 2.4B 和 SigLip-400M 构建,共拥有 2.8B 参数。MiniCPM-V 2.0 具有领先的光学字符识别(OCR)和多模态理解能力。该模型在综合性 OCR 能力评测基准 OCRBench 上达到开源模型最佳水平,甚至在场景文字理解方面实现接近 Gemini Pro 的性能。
面壁动态MiniCPM:揭示端侧大语言模型的无限潜力MiniCPM 是一系列端侧语言大模型,主体语言模型 MiniCPM-2B 具有 2.4B 的非词嵌入参数量。在综合性榜单上与 Mistral-7B 相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型。在当前最接近用户体感的榜单 MTBench 上,MiniCPM-2B 也超越了 Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha 等众多代表性开源大模型。
面壁动态中文多模态大模型VisCPM开放API接口!升级版本能力远超同类模型OpenBMB开源了面壁智能、清华NLP实验室和知乎联合研发的SOTA 开源中文多模态大模型VisCPM。两个多月以来研发同学不断突破,VisCPM得到全新升级。
面壁动态能「说」会「画」, VisCPM:SOTA 开源中文多模态大模型VisCPM 是一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM-Paint模型)。VisCPM基于百亿参数量语言大模型 CPM-Bee(10B)训练,融合视觉编码器(Q-Former)和视觉解码器(Diffusion-UNet)以支持视觉信号的输入和输出。VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
面壁动态官方教程|CPM-Bee在基础任务上的高效微调5月27日百亿参数中英双语基座模型 CPM-Bee 开源之后,在GitHub反响热烈,一度登上总榜第四、Python榜第三。
面壁动态优质野生教程!CPM-Bee部署及创建接口服务CPM-BEE 开源大模型介绍、部署以及创建接口服务
面壁动态填补国产空白!首个联网支持中文问答开源模型WebCPM面壁智能联合来自清华、人大、腾讯的研究人员 共同发布了 中文领域首个基于交互式网页搜索的问答开源模型框架 WebCPM,相关工作录用于自然语言处理顶级会议ACL 2023。
面壁动态登顶 ZeroCLUE!CPM-Bee 凭什么这样强?1月15日,CPM-Bee 模型在 ZeroCLUE 榜单上登顶榜首,距离上一次刷新仅仅四天,并且将总分提高了3.375分,超过了原排名前五的模型间分数提升之和。
面壁动态盼星星盼月亮:首期模型CPM-Ant训练完成啦!盼星星盼月亮,经过一个月的评测与打磨,我们很高兴能够在今天发布 CPM-Ant的全部内容。从大模型训练、微调、推理到应用,不管你是大模型研发者还是大模型技术的爱好者,相信你都能够从 CPM-Ant 的发布内容中有所收获,快来看看吧!
面壁动态ICE:全新智能体跨任务自我进化策略人工智能时代,AI 智能体是否也可以做到,从过去的经验中提取知识并将其应用于未来的挑战中呢?近年来,GPT 和 LLaMA 等语言模型展示了他们在解决复杂任务时的惊人能力。然而,他们尽管可以利用工具解决具体任务,但在本质上缺乏对过去成功和失败经历的洞见与汲取。这就像一个只会完成特定任务的机器人,虽然在完成当下任务上表现出色,但面对新的挑战时,却无法调用过去的经验来提供帮助。
面壁动态面壁智能联合清华发布智能体 GitAgent,拓展大模型智能体实际应用的更多可能性近日,面壁智能联合清华大学和中国人民大学的研究人员,共同发布了 GitAgent,让大模型智能体自主从 GitHub 上扩充自身工具集合,延展自身的能力边界,进一步提升扩大了大模型智能体的应用范围。
面壁动态将 Agent 引入 RPA ,清华联合面壁智能发布流程自动化新范式 APA近日,面壁智能 联合 清华自然语言处理实验室 等机构的研究人员共同发布了新一代流程自动化范式 Agentic Process Automation,该范式不仅实现了工作流构建的自动化,更在工作流执行时引入了动态决策的自动化。这一创新将为未来自动化领域带来更高层次的效率和灵活性,将人类从繁重的劳动中解放出来。
面壁动态ChatDev实现“增量更新”:软件开发效率再再再再提升!ChatDev 又更新了重要功能!开源两个月星标超 1.6+ 万,且多次霸榜 GitHub Trending,火爆国内外的群体智能开源项目 ChatDev 保持着持续不断的技术更新和迭代。
面壁动态ChatDev:大模型AI Agent驱动的虚拟软件公司,荣登GitHub Trending榜首!今年7月,清华大学 NLP 实验室联合面壁智能、北京邮电大学、布朗大学的研究人员共同发布了一个大模型驱动的全流程自动化软件开发框架 ChatDev (Chat-powered Software Development),加入 OpenBMB 大模型工具体系。
面壁动态一个配置文件+几行代码,轻松定制你的简易西部世界!OpenBMB 联合 THUNLP 的研究者们发布了 AgentVerse(多智能体世界)开源项目,旨在为广大研究人员提供一个易于使用、灵活且高度可扩展的平台,以便研究者能够 轻松定制自己的 multi-agent 环境,创建多个具有不同能力与不同身份的 agent,对他们的行为进行观察,或是令他们通过协作和竞争完成复杂任务。
面壁动态大模型工具学习权威综述,BMTools 背后的论文!近期,来自清华大学、中国人民大学、北京邮电大学、UIUC、NYU、CMU等高校的研究人员联合 OpenBMB开源社区、知乎、面壁智能公司探索了基础模型调用外部工具的课题,联合发表了一篇74页的 基础模型工具学习 综述论文,并发布了 开源工具学习平台。该团队提出了基础模型工具学习的概念,系统性地整理和阐述了其 技术框架,同时展示了未来可能面临的 机遇和挑战。这项研究对于了解基础模型工具学习的最新进展及其未来发展趋势具有重要价值。
面壁动态不必排队等 OpenAI Plugins,OpenBMB 开源大模型工具学习引擎2023年3月23日,OpenAI宣布推出插件系统(Plugins),进一步增强了 ChatGPT 的能力。除了ChatGPT自身强大的能力外,Plugins能够支持ChatGPT连接浏览器、数学计算等外部工具,能力大幅增强。这些功能吊起了开发者的胃口,但菜还上不了那么快。迫不及待点进 Plugins 页面,也只能填一个“waitlist”,然后开始漫长的等待。
面壁动态大模型提示学习利器OpenPrompt官方版介绍 | OpenBMB X 清华NLPOpenPrompt 是在 OpenBMB 体系架构图中占据关键位置的 大模型提示学习利器,与 OpenDelta 共同组成 大模型微调套件
面壁动态不止于ZeRO:BMTrain技术原理浅析前期我们发起了 CPM-Live 开源大模型直播训练,与现有的大模型训练使用百余张显卡相比,我们实现了 8 张 A100 显卡 训练百亿大模型。这优异效果的背后基于的是 大模型高效训练工具 BMTrain 和 模型仓库 ModelCenter。与现有框架相比,BMTrain 能够实现大模型的低资源、高效训练,并且简单易用,便于开发者上手。
面壁动态计算成本节省9成:大模型高效训练工具BMTrain2018年,预训练语言模型技术横空出世并引发了人工智能领域的性能革命。研究表明,增大参数量与数据规模是进一步提升语言模型性能的有效手段,对十亿、百亿乃至千亿级大模型的探索成为业界的热门话题。这引发了国内外研究机构与互联网企业的激烈竞争,将模型规模与性能不断推向新的高度。除 Google、OpenAI 等国外知名机构外,近年来国内相关研究机构与公司也异军突起,形成了大模型的研究与应用热潮,人工智能由此进入“大模型时代”。
面壁动态推理超越 Llama3!面壁Ultra对齐助推开源大模型「理科状元」两周前,OpenBMB开源社区联合面壁智能发布领先的开源大模型「Eurux-8x22B 」。相比口碑之作 Llama3-70B,Eurux-8x22B 发布时间更早,综合性能相当,尤其是拥有更强的推理性能——刷新开源大模型推理性能 SOTA,堪称开源大模型中「理科状元」。激活参数仅 39B,支持 64k 上下文,比 Llama3 速度更快、可处理更长文本。
面壁动态强壮全球200个大模型,OpenBMB推动开源社区对齐研究迄今,全球超 200 个模型基于来自 OpenBMB 开源社区的 Ultra Series 数据集(面壁 Ultra 对齐数据集)对齐,数据集包括 UltraFeedback 和 UltraChat,共计月均下载量超 100 万。
面壁动态OpenBMB对齐技术取得新突破,高质量反馈数据助力开源模型面壁智能(ModelBest)与清华 NLP 实验室持续探索大模型对齐(Alignment)技术。继 UltraLM-13B-v1.0 登顶斯坦福 AlpacaEval 开源模型榜单后,近日团队最新发布与 UltraRM 联合的 UltraLM-13B-v2.0(best-of-16采样),在 AlpacaEval 榜单取得了 92.30% 的高分,成为 70B 以下模型最高分。
面壁动态大模型UniMem框架:从记忆增强视角统一长文本处理方法近日,面壁智能(ModelBest)联合清华大学、厦门大学和中国人民大学共同发布大语言模型统一长文本拓展框架 UniMem,从大语言模型记忆增强视角重新构思现有的长文本处理方法。UniMem 通过四个关键维度:记忆管理、记忆写入、记忆读取和记忆注入,提供了一套统一框架来解释各种长文本处理方法。
面壁动态面壁智能联合清华发布DebugBench评测集,探索开源模型的 Debug 之路近日,面壁智能(ModelBest)与清华 NLP 实验室的研究人员共同发布了测评大模型 debug 能力的数据集 DebugBench。这一数据集解决了大模型 debug 领域测评数据稀缺的问题、弥补了现有测试集泄漏风险大、规模小、种类单一的缺陷,为衡量模型 debug 能力提供了更可靠的定量指标。其对于热门大模型的测试结果,揭示了开闭源模型之间的能力差距、不同种类 bug 在不同情景下的修复难度差异,以及 debug 任务和 coding 任务之间的关联性。
面壁动态面壁智能联合清华发布最新多模态对齐框架RLHF-V,减少“过泛化”幻觉达业内最佳水平近日,面壁智能联合清华大学 THUNLP 实验室及新加坡国立大学发表了一篇研究论文,推出全新的多模态大模型对齐框架 RLHF-V,从数据和算法层面入手显著减少“幻觉”的出现。
面壁动态面壁智能给大模型接入16000+真实API,效果直逼ChatGPT!面壁智能联合来自 TsinghuaNLP、耶鲁、人大、腾讯、知乎的研究人员推出 ToolLLM 工具学习框架,加入 OpenBMB 大模型工具体系“全家桶”。ToolLLM 框架包括如何获取高质量工具学习训练数据、模型训练代码和模型自动评测的全流程。作者构建了 ToolBench 数据集,该数据集囊括 16464 个真实世界 API。ToolLLM 框架的推出,有助于促进开源语言模型更好地使用各种工具,增强其复杂场景下推理能力。该创新将有助于研究人员更深入地探索 LLMs 的能力边界,也为更广泛的应用场景敞开了大门。