面壁智能入选2025北京市数字经济标杆企业,以端侧AI夯实数实融合底座7 月 2 日,面壁智能受邀出席 2026 产业互联网创新发展论坛,并凭借在端侧大模型领域的技术创新与产业落地成果,入选“2025北京数字经济标杆企业”榜单
面壁智能亮相2026政法装备展:以AI原生路径推动政法智能化走向业务深处近日,第九届政法智能化建设技术装备及成果展在北京展览馆举行。本届展会以 “AI+智慧政法” 为核心,汇聚华为、科大讯飞等百余家领军企业,全景呈现政法装备领域的前沿技术与创新实践
面壁智能携手澳门国际科技产业中心,共拓海外市场2026年6月30日,澳门——在“澳门国际科技产业中心揭牌仪式暨2026澳门科创莲城InLotuX峰会”上,面壁智能作为首批意向进驻企业,与澳门国际科技产业中心正式签署合作备忘录
面壁智能亮相链博会|以端侧AI全链能力,助力“人工智能+”提速近日,商务部等 8 部门发布相关实施意见,提出加快新一代智能终端、智能网联汽车、AI 硬件等产品发展。随着 AI 从云端能力走向终端设备、产业场景和消费入口,端侧 AI 正成为新一代智能终端升级的重要底座
面壁智能亮相 MBBF:以端侧智能推动移动领域 AI 规模落地近日,MBBF Top Talk Summit 在上海世界会客厅举行。本次大会吸引了来自全球的产业领袖与学者,深入探讨了 AI 与移动通信融合发展,共促 AI 应用繁荣的产业趋势与关键路径
面壁智能曾国洋出席APEC中⼩企业⼯商论坛,以“高效+开源”加速大模型普惠6 月 24 日,以“数智赋能,开放创新,合作共赢”为主题的 2026 年 APEC 中小企业工商论坛在深圳举办
面壁智能CTO曾国洋入选2026 Under36榜单近日,36Kr 暗涌 Waves 2026 年度「 36 Under 36 」名册正式发布,面壁智能联合创始人兼 CTO 曾国洋同宇树科技创始人王兴兴、腾讯首席 AI 科学家姚顺雨
面壁智能李大海:全栈突破×场景落地,端侧AI加速AGI征程在 6 月 12 日举行的北京智源大会上,面壁智能联合创始人兼 CEO 李大海在大模型产业论坛上发表主题演讲
智源大会|技术、应用、生态协同发力 面壁智能描绘端侧AI新图景当大模型突破云端算力桎梏,开始扎根各类终端设备实现感知决策,AI 正在迈入“从云到端”的全新阶段
FlagOS助力 MiniCPM5 在9款芯片(含ARM)适配,Day0实现从云到端生态覆盖,效率追平NVIDIA原生5 月 25 日,面壁智能正式发布并开源了新一代端侧文本基座大模型 MiniCPM5-1B。该模型以 1B 参数规模在 AA-Index 榜单取得 17.9 分,超越 Qwen3.5-2B(16.3 分)等全部 4B 以下开源基座模型,延续了面壁智能提出的"密度定律"——大模型智能密度约每 3.5 个月翻一番。其 Ba
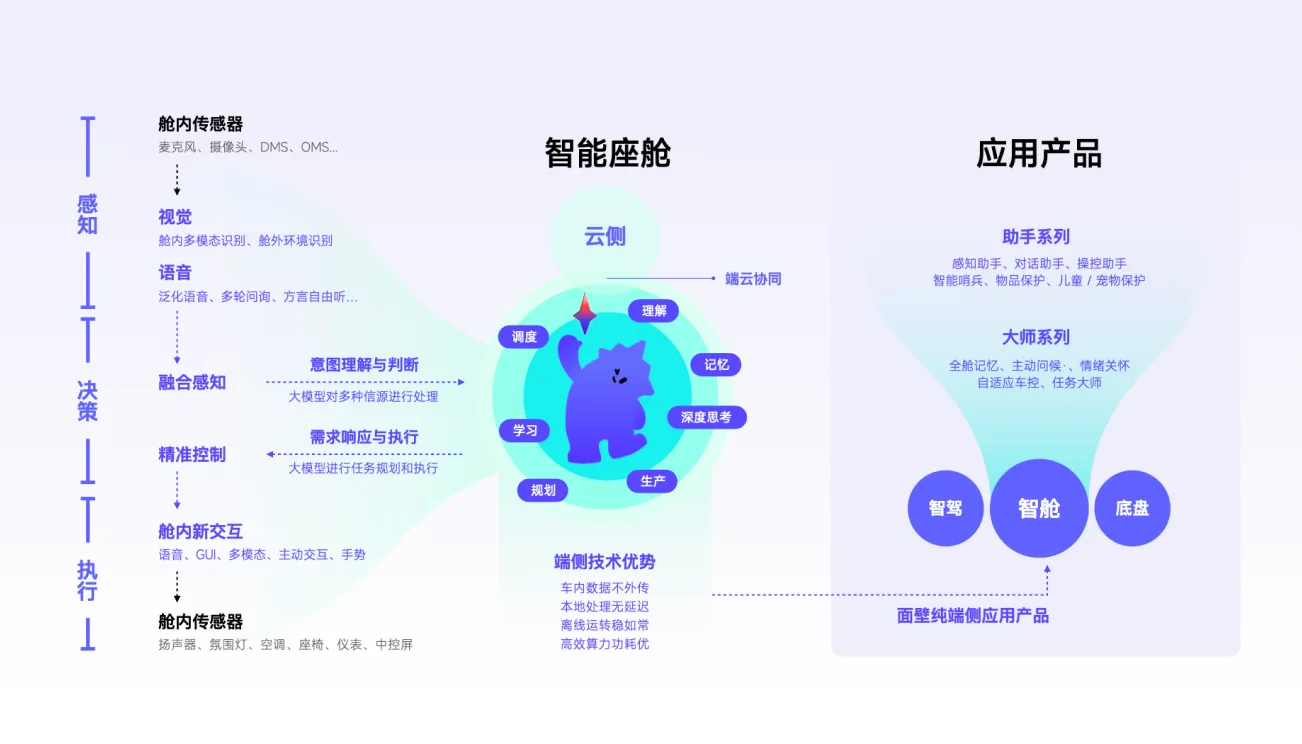
中国智能座舱领跑全球,面壁智能端侧AI打开下阶段想象6 月 4 日,2026 高通汽车技术与合作峰会在无锡启幕。作为高通智能座舱生态的重要伙伴,面壁智能受邀出席并发表演讲,分享端侧大模型在座舱场景的量产实践与未来探索
AI构筑“新丝路”,面壁智能以端侧AI赋能“一带一路”数字合作近日,由人民日报社与吉尔吉斯斯坦《旗帜报》信息出版集团联合主办的中吉媒体合作论坛在吉尔吉斯斯坦比什凯克举办
对话刘知远:中国AI要向外卷,而不只是做第二个OpenAI最早,“有卡就能追”;后来变成“有数据就能追”;再后来,大家发现,即使有钱、有卡、有团队,也未必能做出真正领先的模型。行业开始收敛,玩家开始减少,路线也逐渐分化。 有人继续卷规模,有人转向 Agent,有人下注世界模型
面壁智能CTO曾国洋荣登福布斯亚洲U30榜单近日,福布斯(Global)正式发布“2026 亚洲 30 位 30 岁以下精英榜”(Forbes 30 Under 30 Asia),面壁智能 CTO 曾国洋成功入选
国内首次!面壁智能开源千万级 SFT 与最大中文合成数据,MiniCPM5‑1B 核心数据公开5 月 25 日至 29 日,面壁智能与 OpenBMB 联合举办「端侧大模型开源周」,每天解锁一个端侧大模型的杀手锏。端侧大模型的顶峰,不只在冰山一角,而在整座冰山。今天是开源周的第五弹:UltraData 系列数据集上新
FlagOS助力 MiniCPM5 在9款芯片(含ARM)适配,Day0实现从云到端生态覆盖,效率追平NVIDIA原生5 月 25 日,面壁智能正式发布并开源了新一代端侧文本基座大模型 MiniCPM5-1B。该模型以 1B 参数规模在 AA-Index 榜单取得 17.9 分,超越 Qwen3.5-2B(16.
AI 制造 AI:面壁智能发布并开源全球首个完全由 AI 编写的生产级训练框架 ForgeTrain5 月 25 日至 29 日,面壁智能与 OpenBMB 联合举办「端侧大模型开源周」,每天解锁一个端侧大模型的杀手锏。端侧大模型的顶峰,不只在冰山一角,而在整座冰山
超炫「桌宠」、2B 以下全球最优、开放数据集……MiniCPM5-1B 正式发布并开源!5 月 25 日至 29 日,面壁智能与 OpenBMB 联合举办「端侧大模型开源周」,每天解锁一个端侧大模型的杀手锏。端侧大模型的顶峰,不只在冰山一角,而在整座冰山。今天是开源周的第二弹:端侧文本小钢炮 MiniCPM5-1B
面壁智能联合清华正式开源中国首个基于昇腾训练的 1.58-bit 端侧大模型 BitCPM-CANN5 月 25 日至 29 日,面壁智能与 OpenBMB 联合举办「端侧大模型开源周」,每天解锁一个端侧大模型的杀手锏。端侧大模型的顶峰,不只在冰山一角,而在整座冰山。今天是开源周的第一弹:低比特大模型训练成果 BitCPM-CANN
面壁智能首届实训营收官!学生也能玩转大模型应用开发近日,由广西人工智能学院主办,面壁智能与 OpenBMB 开源社区提供技术支持的“大模型技术与 OpenClaw 应用实战训练营应用创新挑战赛”(以下简称实训营)正式落幕
面壁智能WAIDE秀肌肉:端侧AI已在多行业实现场景突破5月14-16日,以“端启未来·万物新生”为主题的 2026 全球人工智能终端展(WAIDE)暨第七届深圳国际人工智能展览会(GAIE)在深圳举行
新一代「小钢炮」来袭!1.3B 模型性能效率双杀,MiniCPM-V 4.6 正式开源5 月 11 日,面壁智能联合清华大学、OpenBMB 开源社区正式发布并开源了新一代端侧多模态大模型:MiniCPM-V 4.6。 这是 MiniCPM-V 系列有史以来效率与性能平衡最佳的模型。它以仅 1.
智汇时刻回顾丨直击汽车端侧AI白皮书研讨会2026北京车展,面壁智能联合清华大学车辆与运载学院、中国汽车报共同发布《智能座舱:定义 AGI 时代的汽车新范式》行业白皮书,并以“默契之境,智动于心”为主题举办发布会暨研讨会
芯动时刻 默契全程丨面壁智能北京车展回顾✅全模态+全双工:让座舱拥有持续感知的能力,边看边听、边想边说,交互从被动触发走向自然流动的无感陪伴。 ✅AI Box算力魔方:标准化硬件,端侧本地部署。 已与Intel等伙伴合作,2026年底预计有30万辆汽车搭载面壁端侧模型
面壁智能与瑞芯微达成战略合作,端侧"芯片+模型"协同驱动座舱智能升级2026 年 4 月 26 日,北京 —— 第十九届北京国际汽车展览会期间,北京面壁智能科技有限责任公司(以下简称"面壁智能")与瑞芯微电子股份有限公司(以下简称"瑞芯微")正式签署战略合作协议
面壁智能与安波福达成战略合作,端侧AI座舱方案走向全球市场第十九届北京国际汽车展览会期间,北京面壁智能科技有限责任公司(以下简称"面壁智能")与安波福(中国)科技研发有限公司(以下简称"安波福")正式签署战略合作框架协议
端侧智舱启新程 面壁智能以技术创新赋能汽车智能化变革人民日报社主管主办,汽车主流价值传播服务者,有料有趣有观点,让您轻松知晓汽车圈里那些事儿。 当前,全球汽车产业正经历从“电动化上半场”向“智能化下半场”的跨越
全球首个大规模量产AI Box亮相北京车展,面壁智能与英特尔持续深化端侧AI合作第十九届北京国际汽车展览会期间,面壁智能与英特尔联合开发的 AI Box 解决方案在面壁智能展台正式亮相
面壁智能与TINNOVE梧桐科技深化合作,共同探索下一代AI座舱第十九届北京国际汽车展览会期间,北京面壁智能科技有限责任公司(以下简称"面壁智能")与梧桐车联科技有限公司(以下简称"TINNOVE 梧桐科技")宣布进一步深化合作
面壁智能与车联天下达成战略合作,共推端侧AI座舱方案量产落地2026 年 4 月 26 日,北京 —— 第十九届北京国际汽车展览会期间,北京面壁智能科技有限责任公司(以下简称"面壁智能")与无锡车联天下智能科技股份有限公司(以下简称"车联天下")正式签署战略合作协议
《智能座舱:定义AGI时代的汽车新范式》白皮书发布第十九届北京国际汽车展览会期间,面壁智能联合清华大学车辆与运载学院、中国汽车报共同发布《智能座舱:定义 AGI 时代的汽车新范式》白皮书,并举办专题研讨会
面壁智能SuperMate端侧智能座舱方案全新升级亮相北京车展2026 年 4 月 24 日,第十九届北京国际汽车展览会上,面壁智能正式发布 SuperMate 端侧智能座舱方案的全新升级版本
面壁智能亮相全球共享发展行动论坛 以高效大模型技术助力全球南方数字化建设4 月 21 日至 22 日,全球共享发展行动论坛第三届高级别会议在北京举行。本届会议以"坚持行动导向推动构建全球发展命运共同体"为主题,围绕数字赋能、绿色发展、多边合作等全球发展倡议重点领域,进一步凝聚各方共识,探索务实合作路径
EdgeClaw Box 出海首秀,5 大能力助力全球企业 AI Agent 安全落地第四届香港国际创科展现场,面壁智能向全球展示了企业级 AI Agent 安全落地的实力,EdgeClaw Box 样机旁人头涌动。 展会期间,面壁智能向多位国际企业客户详细介绍了 EdgeClaw Box 的产品细节
Lantay 官宣!重度文档人迎来超强外挂这些高严谨行业的打工人,明明满屏 AI 工具,却始终缺一款真正懂行、安全、还趁手的文档外挂。 面壁智能今日推出 Lantay——一款类 Cursor 的专业级文档智能体工作台,目前已进入公测阶段
一人公司的新标配:端云协同的“超级数字员工”越来越多的人不再满足于出卖时间的自由职业,而是开始借助 AI 杠杆,把自己活成了一支能持续盈利的队伍。但伴随实践深入,一个更底层的问题开始被更多人关注到:支撑一人企业运转的 AI 基础设施,应该是什么样的?
面壁智能首创的「密度定律」,获 Meta 等海外顶级机构认可2024 年,面壁智能在海内外第一个前瞻性地提出「密度定律」(Densing Law)——模型智能密度随时间呈指数级增强,达到特定智能水平所需参数量每 3.5 个⽉下降⼀半。 参数量的下降,意味着模型智能密度与芯片算力密度的双向跃升
从云到端:AI部署正在发生一场结构性迁移4月13日至16日,第四届香港国际创科展(InnoEX 2026)将在香港会议展览中心盛大举行。 届时,面壁智能将携 EdgeClaw Box 及行业首个全双工全模态大模型 MiniCPM-o 4.
当《哆啦A梦》开始讲四川话,人人都能当配音师的时代来了语言,声调,音色,情绪,甚至全凭想象,「无中生有」创造一个世界上完全不存在的声音……这是可能实现的目标吗? 当 VoxCPM 2 可以让《哆啦 A 梦》开始讲四川话,全过程 0 人类配音师,答案无需赘述——
深创投、汇川产投联合领投,国家队与产业龙头携手布局面壁端侧大模型近日,面壁智能完成新一轮数亿元人民币融资,由深圳市创新投资集团(深创投)和汇川产投联合领投,道禾长期投资、国泰君安创新投、武岳峰科创等跟投
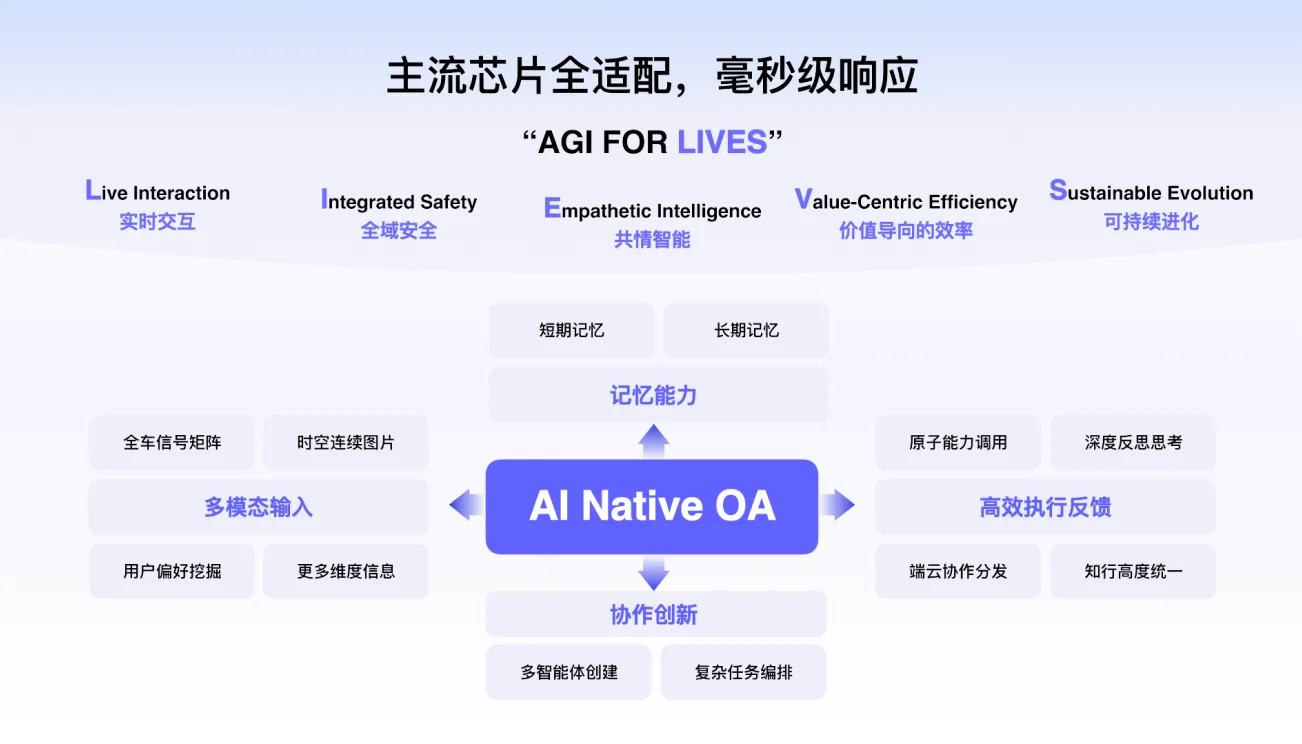
EdgeClaw Box技术架构解析:三级隐私路由与双轨记忆如何运作当AI从问答走向执行,开始处理文档、连接知识库、调用工具、参与业务流程,企业对产品的要求也会随之变化。除了效果,用户同样关注数据如何流转、上下文如何使用、记忆如何沉淀,以及整个处理过程是否能够留在本地、保持可控
破局 Agent 下半场:云端拉开序幕,端侧才是「黄金矿区」近几个月,OpenClaw项目以其惊人的热度,成为了人工智能领域的焦点。它不仅在开源社区获得了超越Linux的历史性关注度,更引发了全行业的迅速跟进。然而,当我们拨开现象级的热潮,深入探究其技术内核时,一个更具战略意义的图景开始浮现
三端齐发!面壁智能在中关村论坛秀出端侧落地"成绩单"2026 中关村论坛年会今日落幕。在这场汇聚全球百余个国家和地区嘉宾的年度科技盛会上,面壁智能带着三款端侧落地产品集中亮相——智能座舱台架、龙虾盒子 EdgeClaw Box、以及与乐聚机器人联合打造的餐吧服务员机器人
博鳌观点|刘知远:从数字世界到物理世界,AI 产业变革的三重奏2026 年 3 月 24 日到 27 日,博鳌亚洲论坛 2026 年年会隆重召开,面壁智能联合创始人、清华大学计算机系教授刘知远受邀出席华商领袖与华人智库圆桌会议,围绕人工智能加速产业变革的主题、企业应对之策作了演讲分享
活动邀请|智能体创新闭门研讨会:OpenClaw 与端侧智能专题端侧智能北京市重点实验室是由面壁智能联合发起的、开展端侧 AI 技术研究与产学研合作的平台
面壁智能 EdgeClaw Box 正式发布:给 OpenClaw 装上「安全大脑」和「省钱开关」OpenClaw 走红,许多人都知道「龙虾」是个好东西,但真正敢将工作交给它的人却不多。为什么?因为一个词:安全
面壁智能开年获数亿元融资,中国电信领投本轮融资规模数亿元,由中国电信领投、中信金石、中信私募跟投。其中,中国电信作为战略投资方,将与面壁智能展开深度业务协同
喜报!面壁智能 3️⃣大成果刷屏!这两天 Hugging Face Trending 太热闹了 —— 面壁智能开源成果一口气占据 3 席! SALA:行业首个大规模训练的稀疏‑线性注意力混合架构,及基于该架构的文本模型 MiniCPM-SALA
创新Transformer!面壁基于稀疏-线性混合架构SALA训练9B模型,端侧跑通百万上下文众所周知,Transformer 及其核心的全注意力机制(Full Attention)虽长期占据大模型架构的核心地位,但平方级计算复杂度、高额显存占用的瓶颈,早已成为实现超长上下文处理与模型规模化应用的 “拦路虎”
治理体系 + 数据上新!UltraData 数据分级治理体系发布,以科学治理赋能 AGI纵观人工智能的发展历程,本质上是一部“数据驱动策略与利用方式”的演进史。每一次范式跃迁,既延伸和重构了前一阶段的数据驱动策略,又演进出新的数据利用方式,从而推动模型能力的跃升与涌现
习近平在北京考察科技创新工作9日上午,习近平总书记来到位于北京亦庄的国家信创园,了解信息技术应用创新和北京加快建设国际科技创新中心情况,察看代表性科技创新成果展示,并同科研人员和科技企业负责人代表亲切交流
MiniCPM-o 4.5开源:「眼耳口」并用,模型交互从「一问一答」变为「即时自由对话」今天,我们开源了新一代全模态旗舰模型 MiniCPM-o 4.5 !作为原生全双工的全模态大模型,MiniCPM-o 4.
坐标已发射,请回答丨面壁急招面壁计划加速,核心技术岗位全线急招。官号专属通道现已开启!
中国 AI 的 2026,四个趋势正成为产业共识近日,新华社发布《2026 年中国 AI 发展趋势前瞻》专题报道。这篇万字长文,指出了中国 AI 产业凝聚共识的四个关键判断。 文章指出,从“拼规模”转向“拼密度”,精炼高效成为大模型演进的核心逻辑之一
DeepResearch 终于本地化了!8B端侧写作智能体AgentCPM-Report开源!在深度研究(DeepResearch)席卷而来的今天,我们都渴望拥有一位可以综合复杂信息、自动撰写万字长文的个人专属“超级写作助手”。但当你手握公司明年的战略规划、未公开的财务报表,或是涉及核心机密的科研数据时,你真的敢把它们上传到云端吗?
面壁获评汽车之心2025「汽车 AI 大模型先锋奖」近日,由《汽车之心》发起的「2025 年度榜单·汽车之星」评选结果揭晓。面壁智能获评 2025 年度「汽车 AI 大模型先锋奖」。 过去一年,我们一直致力于将高效、轻量化的端侧大模型带入驾驶场景
AgentCPM-Explore开源,4B 参数突破端侧智能体模型性能壁垒当全行业还在争论 30B 能否挑战万亿参数时,我们给出了一个更激进的答案: 4B。没有万亿参数的算力堆砌,没有百万级数据的暴力灌入,清华大学自然语言处理实验室、中国人民大学
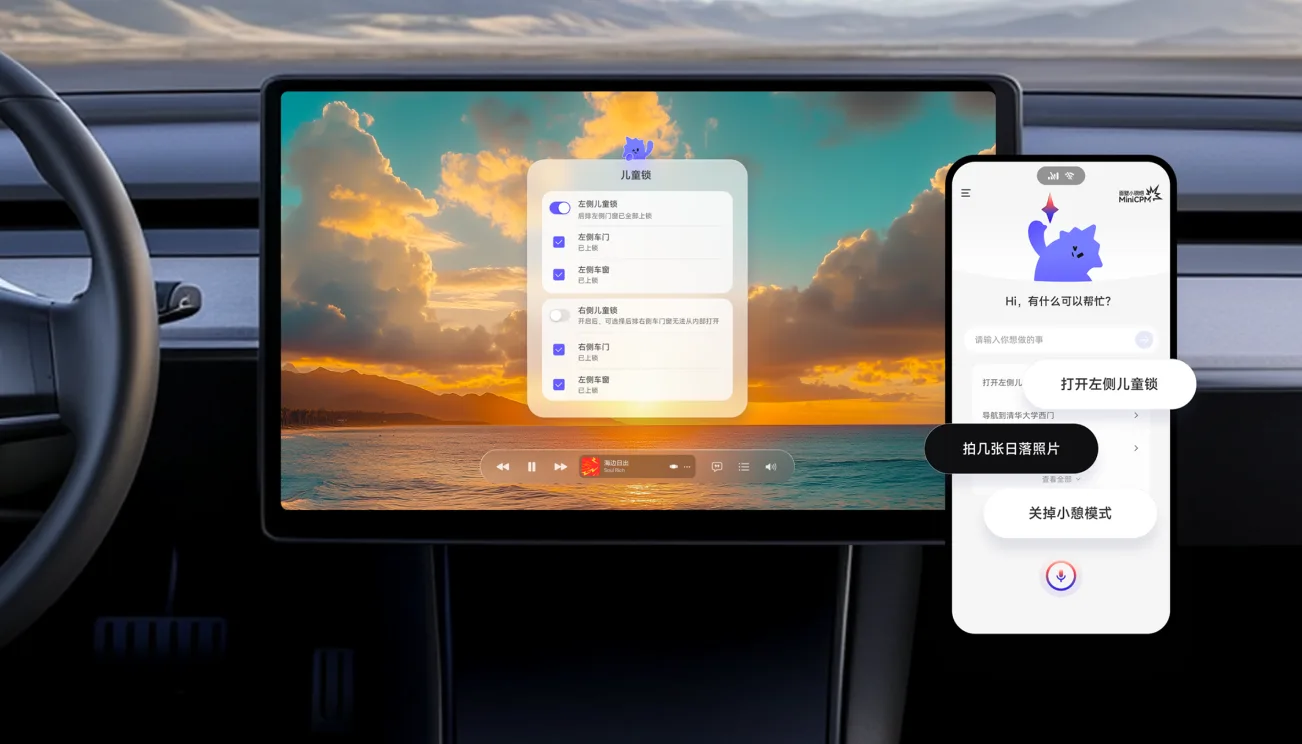
“小钢炮”端侧 VLA 大模型上车!面壁助力吉利银河 M9 打造全新人机交互「AI 科技大六座旗舰 SUV」吉利银河 M9 近日全球上市发布。作为吉利打造的全能旗舰标杆,银河 M9 融合「AI 智能座舱、AI 数字底盘、AI 辅助驾驶」三大 AI 科技,为车主与乘客提供全场景的智慧出行体验。
面壁“小钢炮”登上 Nature 子刊,端侧多模态能力获学术顶级认可7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了面壁「小钢炮」MiniCPM-V 核心研究成果。值得一提的是,这是《Nature》系列期刊第二次刊登面壁智能相关研究成果。MiniCPM-V 是由面壁智能、OpenBMB 团队联合研发的端侧多模态模型,仅依靠 8B 参数实现了多模态综合性能超越 GPT-4V、Gemini Pro 等万亿参数云端模型,并首次在手机、平板、汽车等算力受限的终端设备上实现实时推理的重大突破,也标志着以面壁智能为代表的中国高效大模型技术创新成果获得国际学术界充分认可。
ChatDev 2.0:零代码构建多智能体,快速开发一切还记得之前被吴恩达强烈推荐、连续 7 天霸榜 GitHub Trending 榜首、收获 28k Star 及 3300 次分支复刻
小钢炮风暴,燃爆 2025 上海车展端侧大模型,汽车加速度!
“大模型上车”技术爆发,面壁智能打造超性能「端侧大脑」接管智能座舱!3月30日,面壁智能 CEO 李大海出席 2025 中国电动汽车百人会,并发表主题演讲。他宣布面壁将进军智能座舱领域,推进智能汽车「端侧大脑」开发。以行业首个纯端侧智能助手cpmGO(小钢炮超级助手)为起点,面壁智能正致力于构建车端最强「端侧大脑」,推动智能汽车产品跨越式提升,为用户带来更高阶、更智能的体验。
北京人工智能创新高地建设推进会举行,面壁披露端侧智能最新成果1 月 5 日,2026 北京·人工智能创新高地建设推进会在京举行。会上集中发布了《北京人工智能创新高地建设行动计划》、首批北京人工智能创新街区、北京人工智能前沿成果等多项内容,全面呈现了北京在人工智能领域的硬核科技实力与全栈产业生态
面壁智能共建「端侧智能北京市重点实验室」近日,北京市科学技术委员会、中关村科技园区管理委员会正式公布 2025 年「北京市重点实验室」名单
进击 2025,你好 2026!2025 年 11 月,面壁与清华大学关于「密度法则」的联合研究成果登上《Nature Machine Intelligence》封面
大模型国内首家!面壁通过ASPICE L2 车规级国际评估面壁智能自主研发「端侧芯算融合大模型」项目,近日正式通过 Automotive SPICE(简称ASPICE)L2 级评估
面壁智能完成数亿元融资,加码投入领跑端侧 AI我们高兴地宣布,面壁智能已于近期完成数亿元融资。本次融资由京国瑞、国科投资、中金保时捷基金、米聚资本与和基投资共同参与,募集资金将主要用于加大端侧高效大模型的研发投入,加速端侧 AI 的商业化进程
VoxCPM 1.5 开源,语音生成能力再升级自 VoxCPM 上线以来,我们收到了来自社区及开发者的广泛关注和诸多反馈,促使着 VoxCPM 持续进步。 今天,我们很高兴地和大家宣布, VoxCPM 1.5 版本正式上线,在持续优化开发者开发体验的同时,也带来了多项核心能力升级
面壁智能蝉联VENTURE50「人工智能50」榜单12月4日,2025 VENTURE 50 正式揭晓。面壁智能凭借在人工智能领域的创新实践与快速成长,入选「人工智能 50」榜单
密度定律登《Nature》子刊封面,大模型「高效」路径获学术认可国际顶级学术期刊《Nature》旗下子刊《Nature Machine Intelligence》近日以封面文章形式,刊发了清华大学与面壁智能的联合研究成果《Densing Law of LLMs》
面壁基于第五代骁龙 8 至尊版发布创新端侧智能体 AgentCPM9 月 25 日,2025 高通骁龙峰会·中国期间,面壁智能宣布发布全新 GUI Agent 智能体 AgentCPM,基于面壁 MiniCPM-4V 多模态大模型并面向搭载高通技术公司全新第五代骁龙 8 至尊版移动平台的终端进行优化
面壁与辉羲达成战略合作 加速汽车、具身智能等端侧AI创新9 月 19 日,面壁智能与辉羲智能正式签署战略合作协议,双方将结合各自在大模型算法与 AI 芯片领域的核心优势,共同推进端侧 AI 技术的创新与应用落地,加速高效能 AI 在多元终端场景的规模化普及
面壁小钢炮迎新:VoxCPM 语音生成媲美真人、声音复刻超像!今天,我们隆重介绍面壁小钢炮新成员VoxCPM,一款 0.5B 参数尺寸的语音生成基座模型。该模型由面壁智能与清华大学深圳国际研究生院人机语音交互实验室(THUHCSI)联合研发
全文速递|刘知远分享《大模型智能体发展的关键技术与挑战》在日前举行的上海外滩大会上,清华大学计算机系长聘副教授、面壁智能联合创始人兼首席科学家刘知远发表主题演讲,分享大模型智能体发展的关键技术与挑战。以下是演讲内容(有删节)。 从去年开始,智能体在社会上获得了广泛关注
面壁智能上榜《麻省理工科技评论》“50家聪明公司”9 月 12 日,全球知名技术商业类杂志《麻省理工科技评论》(MIT Technology Review)发布新一届「50 家聪明公司(TR50)」榜单,面壁智能成功入选
基座上新:MiniCPM 4.1 将「高效深思考」引入端侧今天,我们发布新版本的面壁小钢炮 MiniCPM 4.1 基座模型。在 MiniCPM 4.0 的基础上,MiniCPM 4.
最高220倍加速!面壁小钢炮4.0,稀疏创新黑科技大爆发有史以来最具想象力的小钢炮系列,MiniCPM 4.0 来了! 一款 8B 闪电稀疏版,创新稀疏架构掀起高效风暴;一款 0.5B,轻巧灵动的最强小小钢炮。 长长长文本,唰地一下处理完成
科创之光闪耀!面壁智能CEO李大海出席2025北京大学校友科技创新论坛2025 年 5 月 3 日,“2025 北京大学校友科技创新论坛”在北京大学秋林报告厅圆满举行,面壁智能 CEO 李大海与全球顶尖科学家、企业家、创业者与优秀校友代表 300 余人共同出席论坛
首个端侧模型量产车型问世!面壁携手车企伙伴打造车载智能标杆2025 年 4 月 23 日,首款端侧模型量产车型——长安马自达战略级新能源车型 MAZDA EZ-60 正式上市
小钢炮上车,构建汽车机器人「端侧大脑」!电动汽车百人会见3月28日-30日,2025 中国电动汽车百人会论坛将于北京钓鱼台国宾馆举行,以“夯实电动化推进智能化实现高质量发展”为主题,围绕全球及中国汽车电动化发展形势、人工智能、大算力、大模型、大数据等多个话题展开讨论
面壁李大海出席,与图灵奖得主托马斯、罗素、黄铁军、朱军等全球 50+ AI 领袖齐聚中关村继承学术出版严谨与系统,兼具新闻报道及时与多元;为内行搭建思想交流媒介,以事实启迪公众对AI认知。 3月27日-31日,以“新质生产力与全球科技合作”为主题的2025中关村论坛年会将在在北京举行
海淀区委书记张革一行莅临面壁智能调研3月6日,北京市海淀区委书记张革围绕“充分发挥企业创新主体作用,促进民营经济健康发展、高质量发展”主题,到面壁智能开展调研,区领导齐慧超、唐超、赵寒一同参加调研,面壁智能联合创始人刘知远、雷升涛等接待来访并进行座谈
法制日报采访刘知远等研发代表:法律基座大模型将带来哪些“智体验”?今年 11 月,最高人民法院发布了“法信法律基座大模型”(以下简称大模型)。这是最高法积极探索使用人工智能技术为司法赋能,推动人工智能与司法工作深度融合的重要成果
谁是 2024 大模型人气王?在 Hugging Face 「2024 最受欢迎最多下载榜单」中,面壁小钢炮系列 MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.6 双双上榜,并在全球明星大模型版图中占比 2.7%,位列中国模型 TOP1 !
面壁小钢炮,推动端侧 AI 生态建设进行时近日,面壁智能 CTO 曾国洋出席安谋科技(Arm China)主办的「AI 启终端,创‘芯’领航」端侧 AI 生态研讨会,并发表《摩尔定律和面壁定律交汇 MiniCPM 赋能新一代旗舰移动 SoC》主题演讲
Vol 6. Newsletter | 面壁月度精选面壁智能携手英特尔打造高效 AI PC,MiniCPM 端侧模型正获巨大市场推动和技术加速
面壁智能CTO曾国洋入选2024年度“北京市科技新星计划”北京市科学技术委员会、中关村科技园区管理委员会公布了 2024 年“北京市科技新星计划”拟入选人员名单,面壁智能 CTO 曾国洋入选“北京市科技新星计划”创业新星项目。
面壁智能联手大象机器人,带来超级仿真、情感细腻的机器萌宠云端大模型和端侧模型,有一些微妙的价值差异。端侧模型离用户最近,它能快速落地,进入千家万户还伴随着足够强的产品差异化,这也是终端厂商梦寐以求的大模型:经过端侧模型的改造加持,足够凸显原创和异于同品类的体验差异。
面壁智能牵手加速进化机器人,打造端侧模型与具身机器人融合先驱2024 世界机器人大会期间,面壁智能联手加速进化机器人(Booster Robotics),打造出完整“具身智能”的先驱方案,业界首个高效端侧模型运行在人形机器人的演示,理解、推理、并与物理世界互动的智能系统,这激动人心的未来场景,已拉开帷幕!
面壁智能受邀出席《财富》人工智能主题大会大模型是全球瞩目的热门领域,端侧 AI 亦被认为是行业发展下一转折趋势。近日,面壁智能作为中国大模型企业代表,受邀出席正在新加坡举办的 2024《财富》(Fortune)人工智能主题大会。
百度智能云x面壁智能,共同打造大模型端云协同新范式10月30日,面壁智能与百度智能云举行战略合作签约仪式,双方将共同打造大模型端云协同解决方案,共同推动大模型技术加速落地具身智能、智能终端、边缘计算等行业应用。面壁智能联合创始人、CEO李大海,面壁智能COO雷升涛,百度智能云泛科技业务部总经理张玮及双方相关人员出席了本次签约。
面壁智能刘知远:5G-A 与 AI 融合将迎来新发展浪潮随着5G-A商用与入端元年的到来,为社会工作与生活带来了巨大的变化。近日,清华大学副教授、面壁智能联合创始人兼首席科学家刘知远在接受记者采访时表示,“5G-A与AI的融合发展,目前还处于刚刚起步的阶段,未来将会迎来非常大的发展浪潮。”
面壁与MediaTek联合优化新一代移动SoC 芯片10月16日消息,近日,MeidaTek发布新一代3nm制程移动SoC天玑9400,这是面壁智能与MediaTek达成正式合作,联合调校新一代移动SoC 端侧AI能力的全新旗舰芯片。
筑垒加码!长城汽车与面壁智能签署战略合作协议9月27日,长城汽车与面壁智能签署战略合作协议,双方将就大模型技术的研发应用在汽车领域展开深入合作。双方此次合作,旨在围绕长城汽车的AI大模型技术与数据积累,以面壁智能在端侧大模型的研发与应用的全栈能力,与长城汽车多个技术栈进行产品融合、创新,加快长城汽车大模型技术在汽车领域的落地,为长城汽车智慧出行与用户服务的发展提供新的技术动力。
Vol4. Newsletter | 面壁月度精选八月大事记:
💥 发布面壁「小钢炮」 MiniCPM-V 2.6
🎯 小钢炮 2.6 GitHub万星成就达成,登顶GitHub Trending,跻身HuggingFace Trending Top3
🎂 面壁智能两周岁,探索新征程,召唤「新同类」
👯♀️ OpenBMB开源社区开启首批小钢炮挚友计划
🥰 社区活动 · 面壁小钢炮七夕线下品鉴会
👍 面壁智能联合创始人、首席科学家刘知远在世界机器人大会发表演讲
🤩 面壁智能受邀出席《财富》人工智能主题大会
🤝 牵手「加速进化机器人」,打造完整“具身智能”的先驱方案
🐘 与大象机器人达成正式合作
Vol3. Newsletter | 面壁月度精选六七月大事记:
🎯 面壁「小钢炮」 MiniCPM 下载量突破100万
🤖 发布智能体互联网(IoA)
👩🏫 OpenBMB经典大模型课第二季正式上线
🏆 「你好!面壁小钢炮」系列技术教程上线
🤝 与华为连续深化合作,共筑大模型生态
👍 助力全国首个司法审判垂直领域大模型落地,获央视点赞
🔥 携创新之作亮相 WAIC 2024,拉开端侧AI生态序幕
🏅 入选北京市通用人工智能产业创新伙伴计划第三批成员单位
✨ 亮相智源大会,与顶尖大模型公司掌门人共话AGI
📆 面壁学术沙龙第四到六期成功举办
🆓 面壁「小钢炮」 MiniCPM 免费商用
Vol1. Newsletter | 面壁月度精选五月大事记:
🤖 开源大模型「理科状元」Eurux-8x22B 发布
👍 GPT-4V级最强端侧多模态模型发布
📆 面壁学术沙龙第二、三期成功举办
🔎 面壁研究员参加 ICLR 2024学术会议
👀 昇腾开发者大会:面壁智能 CTO 曾国洋发表演讲
💌 5月20日,写给开源社区的情书
🤝 面壁「小钢炮」MiniCPM 在 NAS 行业落地
双登顶!面壁小钢炮3.0 GitHub Top 1,Hugging Face Top 3面壁小钢炮 MiniCPM 3.0 持续引领端侧 ChatGPT 时代!
端侧 ChatGPT 时刻到来!面壁小钢炮 3.0 重磅发布面壁发布小钢炮3.0
星标破万!小钢炮2.6登顶GitHub,Hugging Face TOP3, 燃爆开源社区!想到了直升机,没想到的是火箭! MiniCPM-V 2.6 一经发布,火箭登顶全球著名开源社区 GitHub 与 HuggingFace 趋势榜 Top 3。 至此,面壁小钢炮 MiniCPM-V系列,GitHub 星标破万! 小钢炮MiniCPM系列自今年2月1日面世以来,累计下载量已超百万!
多图、视频首上端!3 SOTA 面壁小钢炮,创 GPT-4V 端侧全面对标新时代!再次刷新端侧多模态天花板,面壁「小钢炮」 MiniCPM-V 2.6 模型重磅上新!
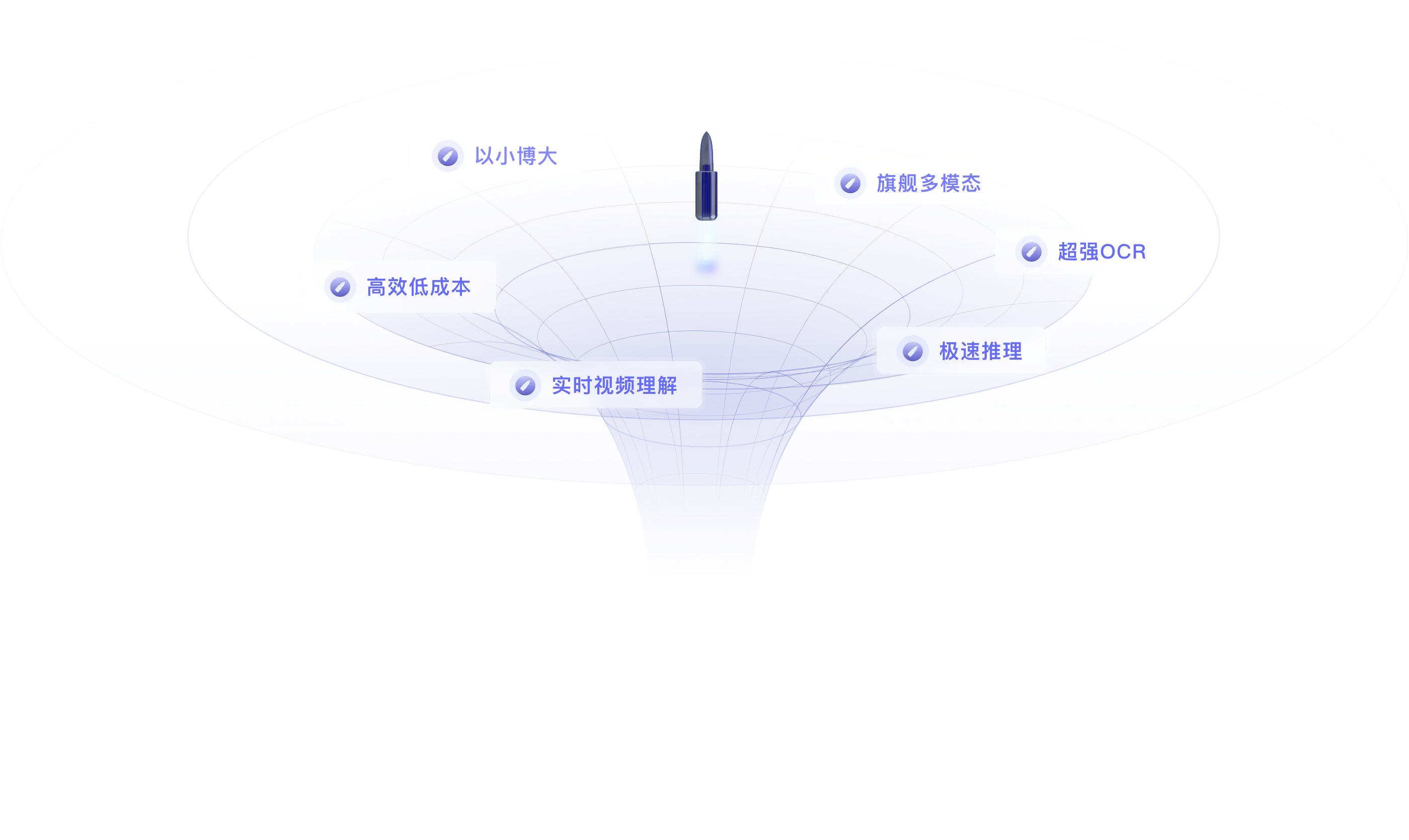
仅 8B 参数,取得 20B 以下单图、多图、视频理解 3 SOTA 成绩,一举将端侧AI多模态能力拉升至全面对标 GPT-4V 水平。
更有多项功能首次上「端」:小钢炮一口气将实时视频理解、多图联合理解、多图 ICL 等能力首次搬上端侧多模态模型,更接近充斥着复杂、模糊、连续实时视觉信息的多模态真实世界,更能充分发挥端侧 AI 传感器富集、贴近用户的优势。
面壁智能与百度智能云达成战略合作,共赴大模型端云协同应用蓝海10 月 30 日,面壁智能与百度智能云举行战略合作签约仪式,双方将共同打造大模型端云协同解决方案,共同推动大模型技术加速落地具身智能、智能终端、边缘计算等行业应用。面壁智能联合创始人、CEO李大海,面壁智能 COO 雷升涛,百度智能云泛科技业务部总经理张玮及双方相关人员出席了本次签约。
面壁联合英特尔深度调校最新一代桌面级旗舰芯片,MiniCPM落地AIPC性能将获跨越式提升10 月 25 日,英特尔酷睿 Ultra 处理器(第二代)品鉴会暨以“强大的 不止 AI ”为主题的 AI PC 生态大会在北京举办,作为英特尔 AI PC 产业生态的重要合作伙伴,面壁智能携手英特尔深度优化采用最新一代 x86 平台的酷睿 Ultra 200S(Arrow Lake)的端侧模型部署和计算加速,在英特尔酷睿 Ultra 处理器和 OpenVINO 工具套件的帮助下,面壁 MiniCPM 端侧模型的 PC 端应用性能得到跨越式提升。
Vol 5. Newsletter | 面壁月度精选登顶全球著名开源社区 GitHub Top1,跻身 HuggingFace 趋势榜 Top 3。 面壁联合英特尔深度调校最新一代桌面级旗舰芯片,MiniCPM落地AI PC性能将获跨越式提升
刘知远做客《人民会客厅》高端访谈,展望AI“入端”的未来机遇近日,面壁联合创始人、首席科学家刘知远做客人民网出品的权威高端访谈栏目《人民会客厅》,与华为公司副总裁、无线网络产品线总裁曹明,TD 产业联盟秘书长杨骅,中国移动首席专家王大鹏一道,共同探讨在移动AI时代下
双登顶!面壁小钢炮3.0 GitHub Top 1,Hugging Face Top 3面壁小钢炮 MiniCPM 3.0 持续引领端侧 ChatGPT 时代!
Vol4. Newsletter | 面壁月度精选小钢炮 2.6 GitHub万星成就达成,登顶GitHub Trending,跻身HuggingFace Trending Top3。 面壁「小钢炮」 MiniCPM-V 2.
面壁智能联手大象机器人,带来超级仿真、情感细腻的机器萌宠云端大模型和端侧模型,有一些微妙的价值差异。端侧模型离用户最近,它能快速落地,进入千家万户还伴随着足够强的产品差异化,这也是终端厂商梦寐以求的大模型:经过端侧模型的改造加持,足够凸显原创和异于同品类的体验差异
面壁2岁了,我们要造一艘巨轮,远航!今天,在每月一度的面壁 TGIF(就是每个月,所有人可以向所有人提问的开诚布公的活动),我们给面壁过了个生日。同学们围在一起,感谢彼此,望向未来。 李大海:感谢面壁所有同学,我们是一个有理想、有斗志、了不起的团队!
面壁两岁了,我们寻找面壁计划的「新同类」新征程,呼唤面壁计划的「新同类」,和我们共同探索「大模型科学化」,把更高知识密度、更高效的大模型,放到离用户最近的地方!
多图、视频首上端!3 SOTA 面壁小钢炮,创 GPT-4V 端侧全面对标新时代!再次刷新端侧多模态天花板,面壁「小钢炮」 MiniCPM-V 2.6 模型重磅上新! 仅 8B 参数,取得 20B 以下单图、多图、视频理解 3 SOTA 成绩,一举将端侧AI多模态能力拉升至全面对标 GPT-4V 水平
Vol3. Newsletter | 面壁月度精选面壁智能窥见异构智能体之间大规模连接协作的“威力”,联合清华大学NLP实验室,正式推出LLM驱动的智能体互联网(Internet of Agents, IoA),跨过异构智能体之间连接、沟通、高效协作存在的沟壑
迈向 IoA 智联网的第一步,面壁将异构智能体“孤岛”连接成完整大陆当前,由大模型驱动、在广泛任务上实现接近人类表现的自主智能体,正在全球各地迅猛发展。正如互联网把全世界所有信息和人连接在一起,物联网把所有设备连接在一起,一个统一的智能体平台把散落在世界各地的智能体连接起来,面壁智能从去年就开始预见
WAIC 2024 ,面壁带来哪些新发布?上海超级“火热”的三天,难挡 WAIC 2024 世界人工智能大会人潮汹涌,每一名专业观众、媒体、行业内和行业外人士,都怀揣着某种迫切和期待
央视新闻点赞!面壁助力全国首个司法审判垂直领域大模型落地面壁智能助力深圳中院,“全国首个司法审判垂直领域大模型” 获央视《朝闻天下》专题报道。 报道称:“ 我国首个正式启用的司法审判垂直领域大模型在世界人工智能大会上做了展示,这套人工智能辅助审判系统实现了从立案到结案的全流程智能辅助
WAIC 2024,面壁打开大模型新定律、新架构、新生态!7月5日,面壁智能联合创始人、首席科学家刘知远在WAIC 2024 “模型即服务(Mass)加速大模型应用落地”论坛进行了《大模型时代的摩尔定律,迈入更高效的大模型时代》主题演讲,并首次对外介绍:
现场直击WAIC 2024!李大海详解高效大模型,面壁成打卡圣地!热҈热҈热҈ ! WAIC 2024,面壁智能热҈到爆҈炸҈ ! 如果用一个词来形容上海今日的天气,那就是——热热热! 如果用一个词来形容WAIC的面壁智能,那就是——热到爆炸!
Vol1. Newsletter | 面壁月度精选MiniCPM-Llama3-V 2.5 实现了「以最小参数,撬动最强性能」的极佳平衡点。 - 取得了超越多模态巨无霸 Gemini Pro 、GPT-4V的多模态综合能力。 - OCR 能力 SOTA!
面壁智能李大海:AI Agent唤醒大模型生产潜力,创造无限应用想象12月14日,量子位“MEET 2024 智能未来大会”在北京举办,20 位来自学术界和产业界的专家与行业领袖共话大模型时代下的思考及实践