








EN

SMALL SIZE, SUPER POWER
Edge Model for Everyone, Everyday, Everywhere
MiniCPM
InsidePhones
MiniCPM
InsideAIPC
MiniCPM
InsideIntelligent
Cabins
MiniCPM
InsideEmbodied
Robots
MiniCPM
InsideWearable
Devices
Put ChatGPT, GPT-4V Level LLMs on Your Phone, Pad and PC
The 'MiniCPM' edge model series is a world-leading, lightweight, and high-performance LLM. Since its release in February 2024, it has been widely tested and acclaimed by the global open-source community for its "achieving more with less" efficiency and outstanding on-device performance. It has repeatedly topped GitHub and Hugging Face trending charts, becoming one of the most popular LLMs on Hugging Face in 2024. The 'MiniCPM' has partnered with industry benchmark leaders, emerging as an indispensable player in driving innovation across sectors such as AIPC, AI phones, intelligent cabins, and embodied robots.

High Efficiency, Low Cost, Achieving More with LessFundation Model MiniCPM

 8B Lightning Edition + 0.5B — Small But Powerful100+x Speed Boost
Proficient in Long-Form On-Device Text
8B Lightning Edition + 0.5B — Small But Powerful100+x Speed Boost
Proficient in Long-Form On-Device Text
Fast!
Inference speed up to 220x ultra-acceleration 5x regular acceleration
Smooth!
Efficient dual-stream sliding window switching Sparse computation for long texts Dense computation for short texts
Powerful!
Punches above its weight with flagship-level performance Requires only 22% of training data to reach comparable quality
Compact!
25% ultra-low storage footprint 90% slimmed-down quantized version Optimized for on-device deployment
4B2.4B1.2B
The On-Device ChatGPT MomentFast!
Inference speed up to 220x ultra-acceleration 5x regular acceleration
Smooth!
Efficient dual-stream sliding window switching Sparse computation for long texts Dense computation for short texts
Powerful!
Punches above its weight with flagship-level performance Requires only 22% of training data to reach comparable quality
Compact!
25% ultra-low storage footprint 90% slimmed-down quantized version Optimized for on-device deployment
View the detailed features of each version
GPT-4o level Omni Model runs on deviceMultimodal Model MiniCPM-V Edge-Side GPT-4oReal-time streaming, end-to-end
Full-modal, all SOTA
The best edge visual general model
The best audio general model
Edge-Side GPT-4oReal-time streaming, end-to-end
Full-modal, all SOTA
The best edge visual general model
The best audio general model
Continuous watching, real videos Not just a single frame-based model Real-time listening, truly smooth Hear clearly, understand distinctly Natural speaking, emotional engagement Real-time interruptions without confusionFull Capability, End-to-EndHigh performance, low latency More natural, more coherent Context understanding Interruptible at any time Noise resistance Easy deployment and maintenanceLearn More
8B Full-Modal8B Live Video8B2.8B
The On-Device GPT-4o New EraContinuous watching, real videos Not just a single frame-based model Real-time listening, truly smooth Hear clearly, understand distinctly Natural speaking, emotional engagement Real-time interruptions without confusionFull Capability, End-to-EndHigh performance, low latency More natural, more coherent Context understanding Interruptible at any time Noise resistance Easy deployment and maintenanceLearn More
View the detailed features of each version
Compare the functionalities of various versions
Global Partner
































Purely On-Device! Superior Performance! Full-Scope Scenarios!
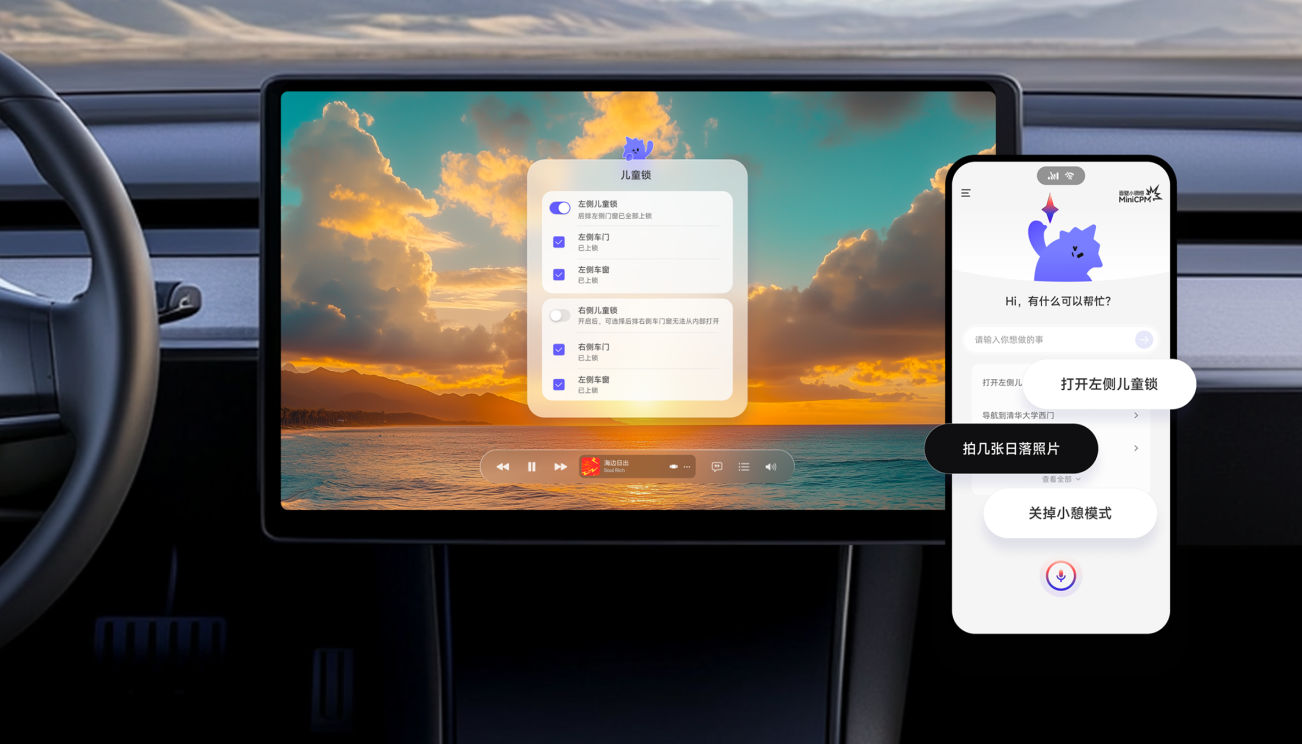
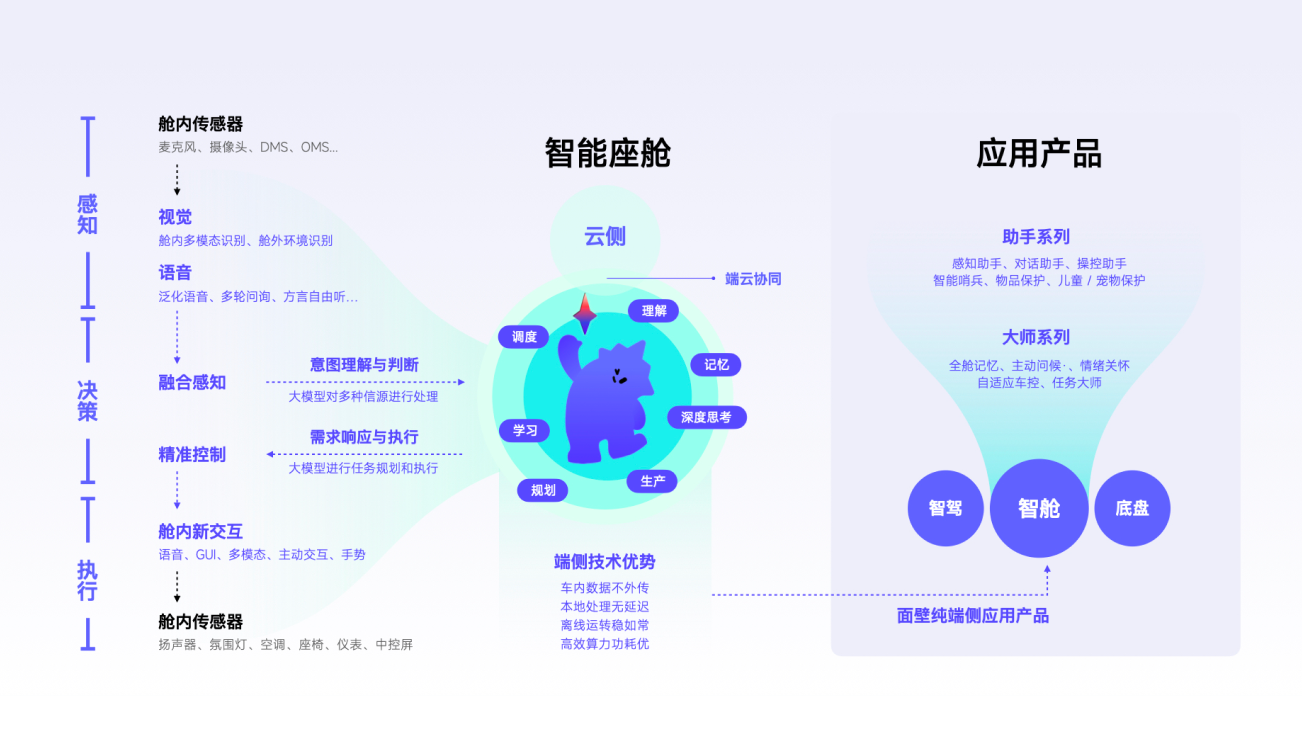
The First Purely On-Device Intelligent Assistant
On-Device Native
Personalized for All Scenarios
Chip-Level Fit
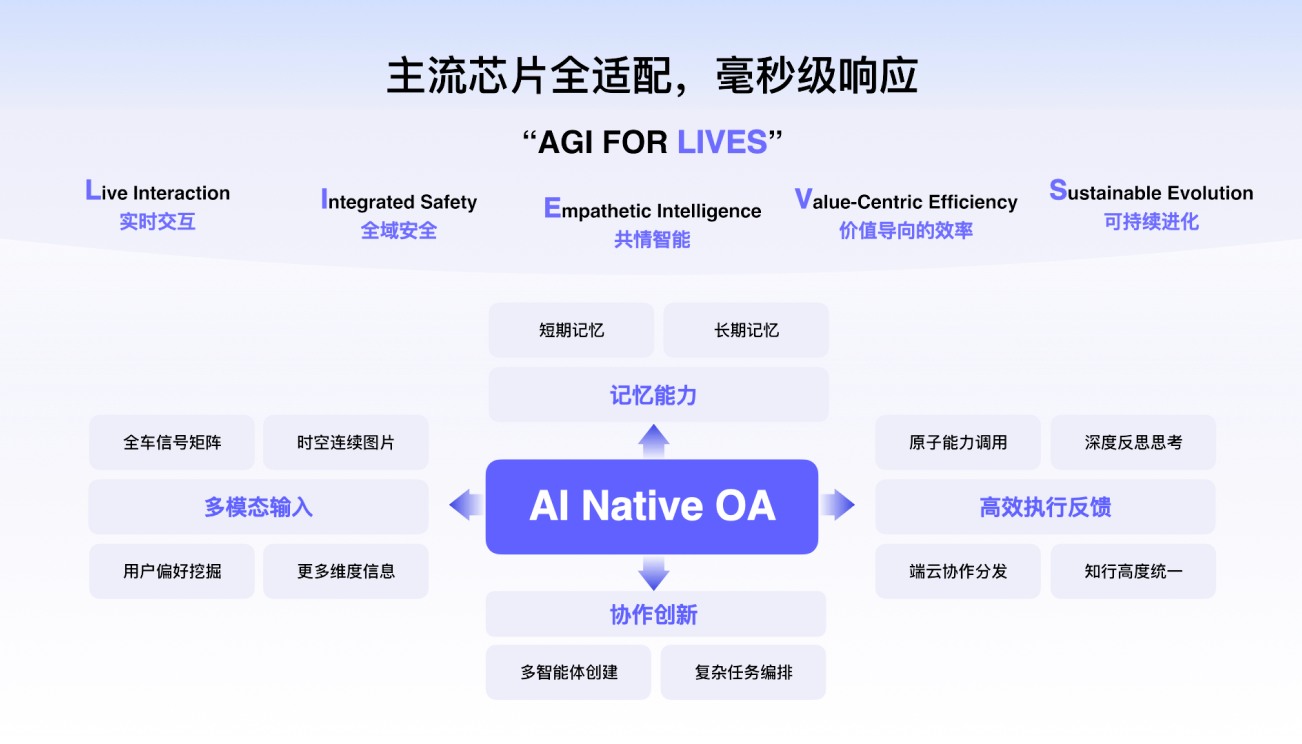
AI Native OA

PLAY
Large Model
Agent
Infra
Ultra Alignment
Others
Efficiency FirstWe believe the best model is the one with superior power, faster speed and lower costEfficiency comes from mastering the science of large language models (LLMs), with knowledge density as the key principle.
As knowledge density grows, it becomes a core competitive advantage, unlocking vast potential for edge intelligence and applications.
Modelbest LawMoore’s Law
Model capability density increases exponentially over time, with the number of parameters required to reach a certain intelligence level halving every 3.3 months.Capability density: The ratio of effective parameter size to actual parameter size. Effective parameter size refers to the minimum number of parameters required for the reference model (e.g., MiniCPM) to achieve performance equivalent to the given target model.
A G I F O R L I V E S