


高效模型解决方案技术Blog了解我们新闻动态OpenBMB开源社区加入我们
模型产品
松果派 Pinea兰台令 Lantay
中文
中文ENعربيESFRRUPT

把大模型放到离用户最近的地方
做高效的端侧智能
高效手机
高效AIPC
高效智能座舱
高效具身机器人
高效可穿戴设备
旗舰端侧大模型系列 大模型科学化结晶
全球领先的轻量高性能大模型,可有效运行在日常生活中主流消费电子和各类终端上,覆盖不同的芯片和系统平台。 MiniCPM系列端侧模型,拥有极致的算力和内存使用效率,参数量更小、推理速度更快、性能越级比肩、部署高度灵活和简洁。 「模型制程」也在持续提升中,大模型科学化不断向更深更远的无人区探索,不断地惊喜收获。
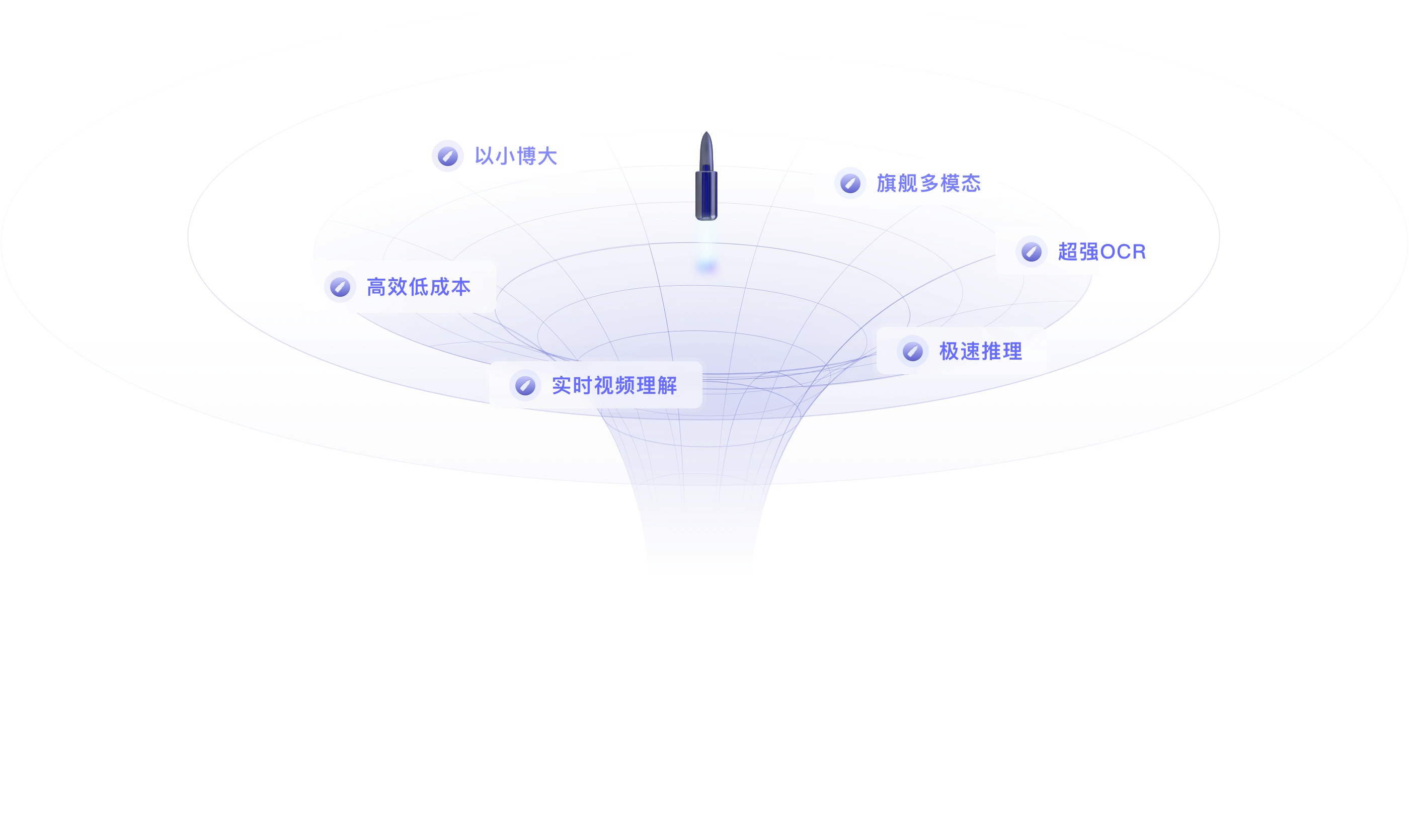
极致以小搏大 + 极致高效低成本旗舰基座模型 MiniCPM

 8B 稀疏闪电版 + 0.5B 以小博大百倍提速
开启端侧长文本时代!
8B 稀疏闪电版 + 0.5B 以小博大百倍提速
开启端侧长文本时代!
快!
推理速度 220 倍极限加速 5 倍常规加速
顺!
高效双频丝滑换挡 长文本用稀疏 短文本用稠密
强!
以小博大的旗舰性能 训练开销仅需 22%
小!
25% 极低存储空间 量化版 90% 瘦身 端侧部署友好
 以小博大
强得不像端侧模型!ChatGPT 级基础性能
以小博大
强得不像端侧模型!ChatGPT 级基础性能
超 GPT 3.5,Qwen2-7B,GLM4-9B
新架构,知识密度新高
见证知识密度每8个月翻一番
轻!快!端侧友好
量化后仅 2GB 内存
全面开挂 全,瑞士军刀;强,刀刀锋利超 Kimi!「无限」长文本
32,128,256,512K…上下文无限拓展
GPT-4o 级 Function Calling
超越 GPT-3.5,GLM4-9B,近 GPT-4o
超强 RAG 外挂三件套
中文检索第一,生成超 Llama3-8B了解更多 越级超越 全球标杆之作Mistral-7B, Llama2-13B,
Gemma-7b-it, ChatGLM3-6B等
是小尺寸高性能的开源模型明星高效率 低成本支持 CPU 推理,消费级显卡微调
推理速度高至 33 tokens/s
推理成本低至1元=1700000 tokens*推理速度为英特尔® 酷睿™ ULTRA 9处理器实践表现;
*推理速度按照骁龙 855 芯片,成本约 600 元人民币,按照运行 5 年计算,每秒 7.5 tokens了解更多
越级超越 全球标杆之作Mistral-7B, Llama2-13B,
Gemma-7b-it, ChatGLM3-6B等
是小尺寸高性能的开源模型明星高效率 低成本支持 CPU 推理,消费级显卡微调
推理速度高至 33 tokens/s
推理成本低至1元=1700000 tokens*推理速度为英特尔® 酷睿™ ULTRA 9处理器实践表现;
*推理速度按照骁龙 855 芯片,成本约 600 元人民币,按照运行 5 年计算,每秒 7.5 tokens了解更多 小尺寸 适配更多端侧场景一半体量,性能超越 Llama2-13B
推理速度 25tokens/s, 25倍人类语速
推理成本下降 60%
1 元=4150000 tokens*苹果A17 Pro为130美元(约人民币950元), 如开metal, 速度最大为 25 tokens/s,芯片使用5年,推理代价为 (25×3600×24×365×5)/950=415万 tokens/元了解更多
小尺寸 适配更多端侧场景一半体量,性能超越 Llama2-13B
推理速度 25tokens/s, 25倍人类语速
推理成本下降 60%
1 元=4150000 tokens*苹果A17 Pro为130美元(约人民币950元), 如开metal, 速度最大为 25 tokens/s,芯片使用5年,推理代价为 (25×3600×24×365×5)/950=415万 tokens/元了解更多
4B2.4B1.2B、极速版
越级超越 全球标杆之作快!
推理速度 220 倍极限加速 5 倍常规加速
顺!
高效双频丝滑换挡 长文本用稀疏 短文本用稠密
强!
以小博大的旗舰性能 训练开销仅需 22%
小!
25% 极低存储空间 量化版 90% 瘦身 端侧部署友好
超 GPT 3.5,Qwen2-7B,GLM4-9B
新架构,知识密度新高
见证知识密度每8个月翻一番
轻!快!端侧友好
量化后仅 2GB 内存
全面开挂 全,瑞士军刀;强,刀刀锋利超 Kimi!「无限」长文本
32,128,256,512K…上下文无限拓展
GPT-4o 级 Function Calling
超越 GPT-3.5,GLM4-9B,近 GPT-4o
超强 RAG 外挂三件套
中文检索第一,生成超 Llama3-8B了解更多
查看各个版本的功能详情
视频、多图、单图,全面超越 GPT-4o旗舰多模态模型 MiniCPM-V 实时流式,端到端,全模态
持续看、实时听、自然说最强多模态实时流式交互
最强端侧视觉通用模型
最强语音通用模型
实时流式,端到端,全模态
持续看、实时听、自然说最强多模态实时流式交互
最强端侧视觉通用模型
最强语音通用模型
持续看,真流式,贴近人眼自然视觉交互 实时听,真流畅,具备抗噪能力,可识别背景音情境 自然说,带感情,超拟人情感对话,真人质感语音生成、语音克隆,可实时打断,更自然更连贯全实力,端到端小参数,全模态,端侧简单部署维护 真流式视频,端到端语音,高性能、低延迟了解更多 最强端侧多模态多项能力综合性能实时视频理解、多图、单图取得 20B 以下模型 3 SOTA
开启端侧全面对标 GPT-4V 新时代3 项重磅功能,首次上端实时视频理解
多图联合理解
多图 ICL 视觉类比学习轻!快!端侧友好!量化后端侧内存仅 6 GB
端侧推理速度高达 18 tokens/s,快 33%
支持 llama.cpp、ollama、vllm 推理其他180 万像素高清 OCR,超越 GPT-4o、GPT-4V 和 Gemini 1.5 Pro 等
极致高效,最高多模态像素密度,两倍于 GPT-4o 的单 token 编码像素密度自研 RLHF-V 高效对齐技术,极低幻觉
可信多模态行为,优于 GPT-4o 和 GPT-4V了解更多
最强端侧多模态多项能力综合性能实时视频理解、多图、单图取得 20B 以下模型 3 SOTA
开启端侧全面对标 GPT-4V 新时代3 项重磅功能,首次上端实时视频理解
多图联合理解
多图 ICL 视觉类比学习轻!快!端侧友好!量化后端侧内存仅 6 GB
端侧推理速度高达 18 tokens/s,快 33%
支持 llama.cpp、ollama、vllm 推理其他180 万像素高清 OCR,超越 GPT-4o、GPT-4V 和 Gemini 1.5 Pro 等
极致高效,最高多模态像素密度,两倍于 GPT-4o 的单 token 编码像素密度自研 RLHF-V 高效对齐技术,极低幻觉
可信多模态行为,优于 GPT-4o 和 GPT-4V了解更多 最强端侧多模态通用能力超越巨无霸 Gemini Pro 、GPT-4V最强端侧OCR
比肩GPT-4V级标杆模型OCRBench 榜单越级超越 GPT-4o、
GPT-4V、Claude 3V Opus、Gemini Pro 等标杆模型9倍像素更清晰
难图长图长文本精准识别自研高清图像高效解码技术,端侧无损识别 180 万像素高清图片,支持任意长宽比,难图出色解读与推理,长图长文本 OCR 精准识别提取
最强端侧多模态通用能力超越巨无霸 Gemini Pro 、GPT-4V最强端侧OCR
比肩GPT-4V级标杆模型OCRBench 榜单越级超越 GPT-4o、
GPT-4V、Claude 3V Opus、Gemini Pro 等标杆模型9倍像素更清晰
难图长图长文本精准识别自研高清图像高效解码技术,端侧无损识别 180 万像素高清图片,支持任意长宽比,难图出色解读与推理,长图长文本 OCR 精准识别提取 端侧系统级多模态加速图像编码快 150 倍!
手机端 6-8 tokens/s 高效运行支持30+多种语言新增德语、法语、西班牙语、意大利语、俄语等主流语言和多个小语种了解更多
端侧系统级多模态加速图像编码快 150 倍!
手机端 6-8 tokens/s 高效运行支持30+多种语言新增德语、法语、西班牙语、意大利语、俄语等主流语言和多个小语种了解更多
8B全模态8B实时视频8B2.8B
最强端侧多模态通用能力持续看,真流式,贴近人眼自然视觉交互 实时听,真流畅,具备抗噪能力,可识别背景音情境 自然说,带感情,超拟人情感对话,真人质感语音生成、语音克隆,可实时打断,更自然更连贯全实力,端到端小参数,全模态,端侧简单部署维护 真流式视频,端到端语音,高性能、低延迟了解更多
查看各个版本的功能详情
查看各个版本的功能对比
全球合作伙伴
































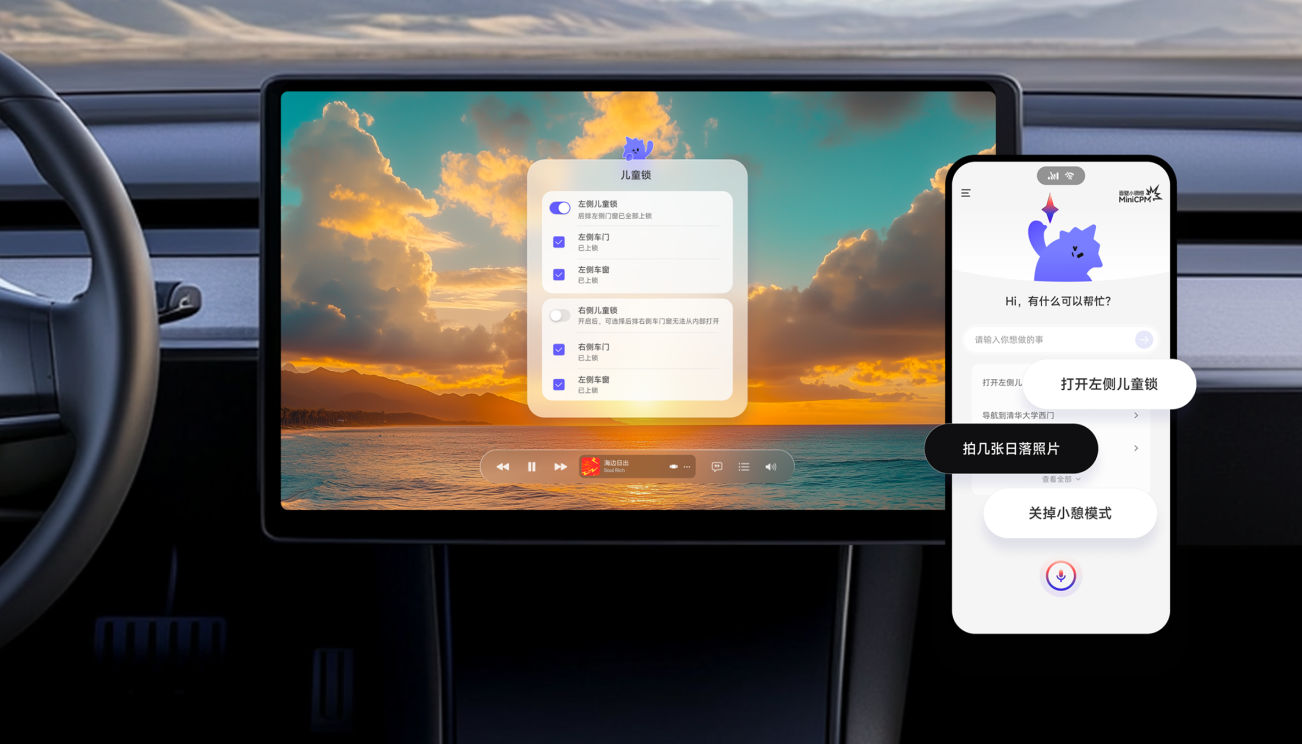
纯端侧!超性能!全场景!首个纯端侧智能助手
了解更多创造智能座舱
「原生端侧体验」
全场景原子产品
个性化选配
主流汽车芯片
全适配
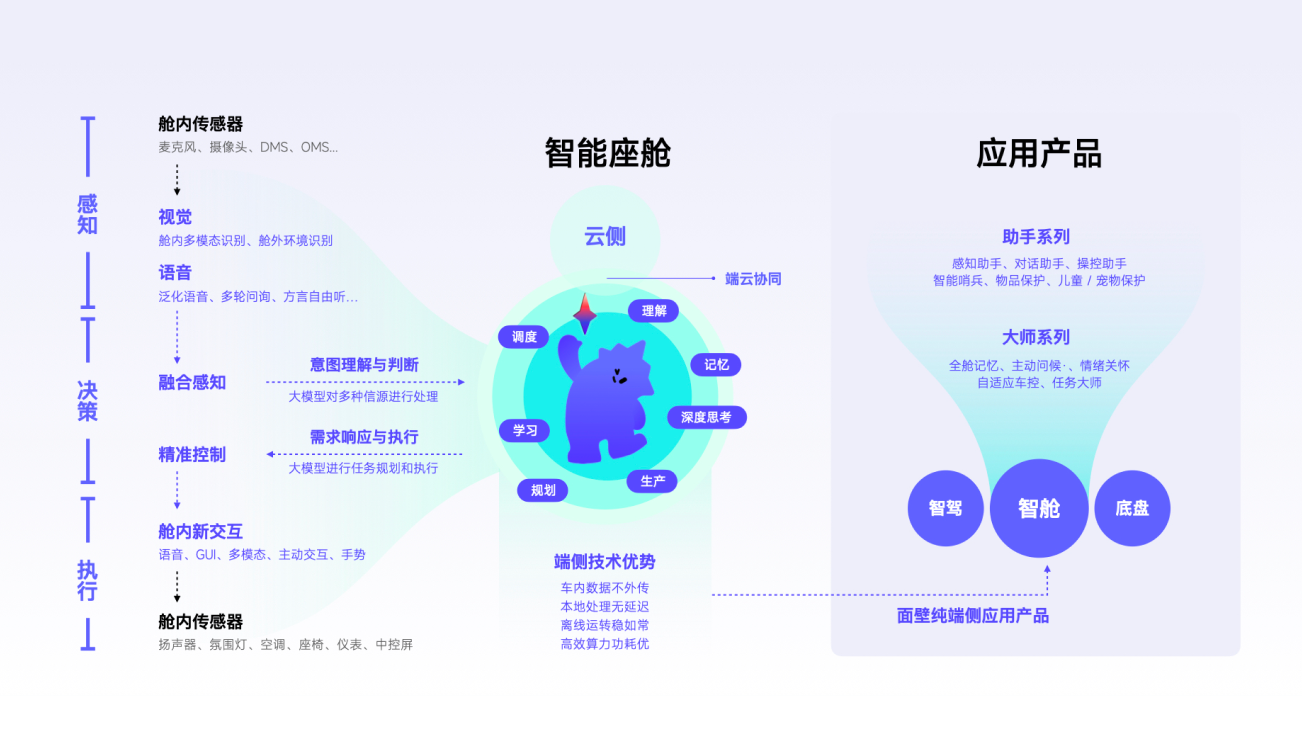
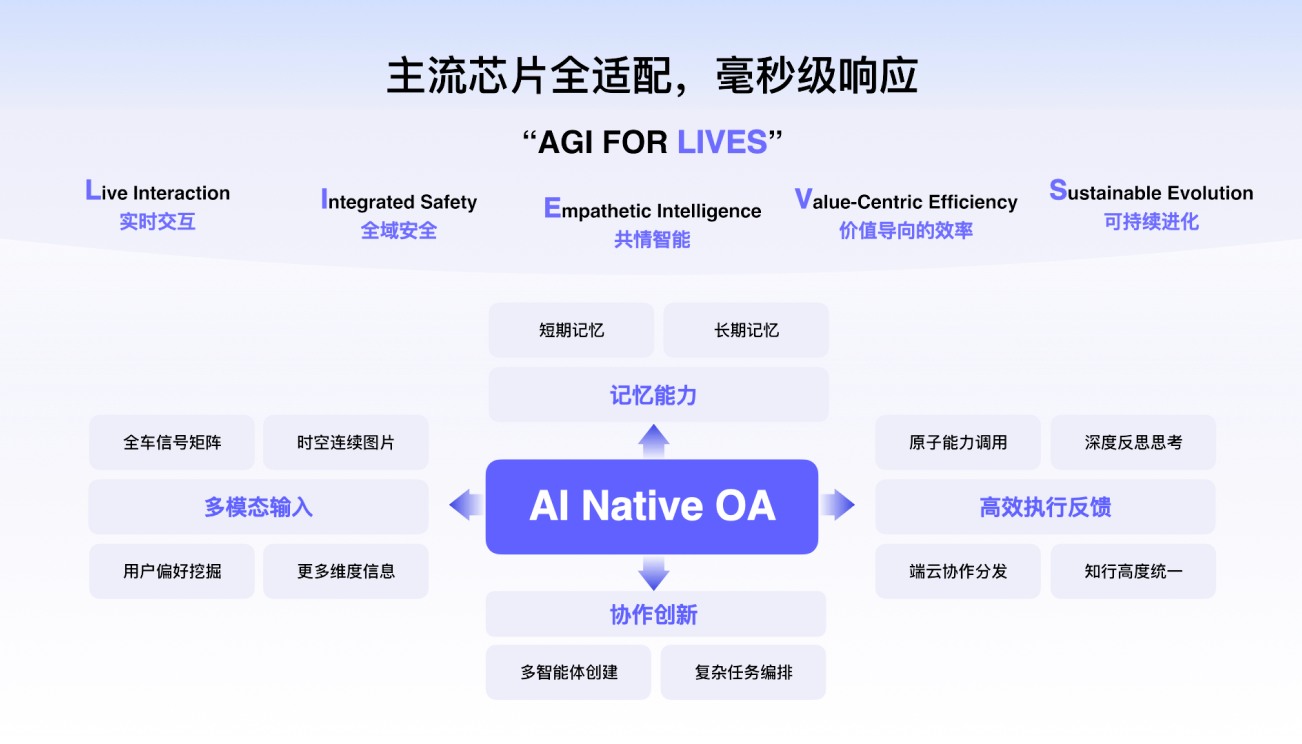
AI Native OA

播放视频
AI+法律=高质量法治和高水平司法全国首个接入法院
办案流程的大模型了解更多每份案件后面,都是一份沉甸甸的期待。如何让正义,更快来到人们身边?同时让从业人员从繁琐流程中获得解脱?
高效,是大模型的强项,也是我们的强项!我们的大模型,围绕“公正与效率”主题,实现全流程AI赋能,已在法院专网完成部署并服务专业司法场景。
法律行业权威知识库深度合作,赋予我们更强的专业性。我们致力于通过提供高效可落地的大模型解决方案,以及自主可控的大模型能力,为法律业务赋能增效。
全球前沿Agent技术迈向IoA
智能互联时代了解更多互联网将全世界所有信息带到用户面前,物联网让所有设备相互连接共享信息。
在未来,通过大模型驱动的Agent平台,可以在更多用户、信息和设备之间建立连接,创造全新智能应用场景,进一步解放生产力,加速迈向“Internet of Agents”新时代。
我们已创建了 ChatDev、 X-Agent、AgentVerse 等多个单体智能、群体智能、智能协作方面的Agent明星项目。
大模型
Agent
Infra
Ultra对齐
其他
新版 UltraEval-Audio 开源:新增一键复现、隔离推理运行机制,让模型测评更高效、更可控如今,音频模型已经成为重要的生产力工具,对研究者而言,如何提高音频模型的性能和效果是重中之重。在音频模型快速更新的背景下,研究者普遍面临以下几类问题,导致研发效率低下:第一,论文与公开报告中的指标往往难以在本地稳定复现,复现流程依赖零散脚本、隐藏参数与复杂前后处理,导致“结果对不上、过程跑不通”;第二,不同模型对运行环境的要求差异巨大(框架版本、CUDA 依赖、第三方库互斥等),在同一台机器上并行评测多个模型时极易陷入依赖冲突与环境反复重装的问题。第三,除通用语音大模型外,TTS、ASR、Codec 等专有音频模型在社区与产业侧的关注度持续提升、热门模型与方案快速涌现,围绕这些模型的“可复现评测”需求也显著增长。基于上述痛点,清华、OpenBMB、面壁智能联合发布 UltraEval-Audio v1.1 版本,在原有的“一键测评”音频模型的基础上,重点新增热门音频模型的一键复现能力,扩展对 TTS/ASR/Codec 等专业模型与专项评测的支持,并引入隔离推理运行机制,以在工程层面降低复现门槛、提升评测流程的可控性与可迁移性。
清华首发语音大模型评测工作,评测框架、竞技场、榜单全系开放近年来,大模型技术正从单一的文本模态向多模态领域快速扩展,发展势头迅猛。特别是在2024年5月,OpenAI 发布了具备多模态能力的 GPT-4o,再次引领了大模型的研究方向与技术潮流,推动了多模态模型的蓬勃发展。在此背景下,清华 NLP 实验室、OpenBMB 与面壁智能联合推出首个全模态语音大模型评测框架 UltraEval-Audio 以及 AudioArena 语音大模型 PK 平台。通过专业、定量、科学的评测方法全面评估了当前市场上语音大模型的性能,并发布了首个权威的语音测评榜单 UltraEval-Audio-Leaderboard,为语音大模型行业提供龙虎榜。
VoxCPM 登顶 HuggingFace TOP1面壁小钢炮首款语音生成模型 VoxCPM 一经发布,广受好评,成功登顶 HuggingFace TOP1。
面壁小钢炮迎新:VoxCPM 语音生成媲美真人、声音复刻超像!今天,我们隆重介绍面壁小钢炮新成员VoxCPM,一款 0.5B 参数尺寸的语音生成基座模型。该模型由面壁智能与清华大学深圳国际研究生院人机语音交互实验室(THUHCSI)联合研发。
MiniCPM-V 4.5 技术报告正式出炉今天,MiniCPM-V 4.5 技术报告正式出炉。报告从模型结构、训练数据和训练策略三个维度探索了高效多模态大模型的实现路径,以解决多模态大模型的训练和推理的效率瓶颈。提出 统一的 3D-Resampler 架构实现高密度视频压缩、面向文档的统一 OCR 和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。基于这些关键技术,MiniCPM-V 4.5 在视频理解、图像理解、OCR、文档解析等多项任务上取得显著突破,不仅以 8B 的参数规模超越 GPT-4o-latest 和 Qwen2.5-VL-72B,更在推理速度上具有显著优势。
MiniCPM-V 4.5 登上 HuggingFace TOP2面壁最新诚意之作 MiniCPM-V 4.5,8B 小身材爆发超高性能,高刷视频理解被称为「鹰眼级」,一经开源,就收获了开发者的热情回应,登上 HuggingFace Trending TOP2。
多模态新旗舰MiniCPM-V 4.5:8B 性能超越 72B,高刷视频理解又准又快今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。
MiniCPM-V4.0开源,多模态能力进化,手机可用,还有最全CookBook!MiniCPM-V 4.0 以 4B 的参数量真正做到了稳定运行、快速响应,且在手机、平板等设备长时间连续使用无发热、无卡顿。
面壁“小钢炮”登上 Nature 子刊,8B 多模态综合性能超越 GPT-4V、Gemini Pro7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。
MiniCPM-o 2.6 技术博客为了促进开源社区的探索,我们推出了 MiniCPM-o 2.6,一个从 MiniCPM-V 系列升级而来的最新性能最佳的端侧多模态大模型。该模型接受图像、视频、文本和音频输入,并以端到端方式生成高质量的文本和语音输出。虽然总参数量仅有 8B,MiniCPM-o 2.6 的视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别,是开源社区中模态支持最丰富、性能最佳的模型之一。
H-Neurons:大语言模型中幻觉相关神经元的存在、作用及其起源清华大学 THUNLP、清华大学新闻与传播学院、OpenBMB 以及面壁智能的联合团队近期的一项工作《H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs》从微观神经元视角出发,系统研究了 LLM 中的幻觉机制:不仅找到了与幻觉相关的极少数神经元(H-Neurons),更揭示了一个令人意外的真相:幻觉并非无序的生成错误,而是模型为了顺从你进行的“过度配合”。
基座上新:MiniCPM 4.1 将「高效深思考」引入端侧今天,我们发布新版本的面壁小钢炮 MiniCPM 4.1 基座模型。在 MiniCPM 4.0 的基础上,MiniCPM 4.1 新增 8B 参数的行业首个原生稀疏架构深思考模型,同级 SOTA 表现带来超快、超准的深思考能力,真正让端侧设备实现高效「深思考」。
技术Blog-9|ArkInfer:面向端侧AI的跨平台高效部署系统如何突破硬件壁垒,实现“一次开发,处处运行”?这一问题的核心在于 解耦与代码复用 ——即将算法创新与底层硬件实现解耦,让单一的工程成果能够自动、高效地应用于多个平台。为解决上述痛点,我们提出了 ArkInfer,一个创新的、面向未来的跨平台 AI 模型部署系统。ArkInfer 旨在通过提供极致的推理效率和卓越的平台兼容性,彻底克服端侧芯片碎片化带来的障碍,为各类模型应用提供坚实的部署基石。
技术Blog-8 | Chunk-wise Rollout:基于分块采样的高吞吐强化学习加速策略Chunk-wise Rollout 是一种加速 RL 训练的策略,通过对 RL 训练流程进行异步化,限制每次采样过程中每条轨迹的最大生成长度,并在下一次采样中复用本轮中未生成完毕的轨迹,从而减小采样过程中因部分超长轨迹造成的计算空泡,提升 GPU 利用率。同时,为了减小引入 Chunk-wise Rollout 策略带来的离线采样数据对训练效果和稳定性的影响,我们引入了多项策略,包括 分块级重要性采样、双向裁剪、 KL 正则约束与动态参考模型更新 以及 异常内容过滤。 这些策略共同实现了稳定且高效的 RL 训练,在实现了 2.05 倍训练加速的同时取得了和常规 RL 训练方式相近甚至超越的效果。
技术Blog-7 | BitCPM:极低位宽的模型量化极低位宽的模型量化近年来一直是学术界研究的热点,也涌现出了许多效果显著的工作。对于如何使用 QAT 方法高效训练出极低位宽的模型,我们在 MiniCPM 系列模型上进行了实验探索,并推出了我们的低位宽模型 BitCPM 系列。
技术Blog-6 | 风洞 2.0:高效的模型训练最优超参数搜索方法早在训练 MiniCPM1 的时候,面壁团队就已经使用了模型风洞实验来指导模型的训练,本次我们使用了更有效的模型评估方法,同时对模型风洞流程进行了一些升级,提升了我们的参数搜索的效率。同时我们将风洞方案和业界有代表性的超参搜索方案进行了对比。
技术Blog-5 | MiniCPM4-Survey:基于多步智能体强化学习的可信长综述生成技术随着 OpenAI 等机构陆续推出 DeepResearch(深度研究)系统,大模型的实际应用中增添了一项重要任务:生成长篇幅、多引用、结构化的综述报告。然而,目前市面上的多数解决方案依赖于闭源的大参数规模模型,使用成本较高、调用次数受限。为了解决这一问题,让更多用户在更广泛的场景中能够使用综述报告生成功能,我们重点探索了多步智能体强化学习(Multi-Step Agent Reinforcement Learning)方法,推出以端侧级参数规模完成可信长综述生成的 MiniCPM4-Survey。其生成的综述文章质量在多个维度的对比中可以比肩 OpenAI Deep Research。
MiniCPM 4.0 部署及微调教程MiniCPM 4.0 推出端侧性能“大小王”组合,拥有 8B 、0.5B 两种参数规模,延续「以小博大」特性,实现了同级最佳的模型性能。其中,MiniCPM 4.0 -8B 是首个原生稀疏模型,5% 的极高稀疏度加持系统级创新技术的大爆发,让长文本、深思考在端侧真正跑起来,以仅 22% 的训练开销,性能比肩 Qwen-3-8B,超越Gemma-3-12B。MiniCPM4.0 -0.5B 取得同级 SOTA,并通过原生 QAT 技术实现几乎不掉点的 int4 量化,实现了 600 Token/s 的极速推理速度。
技术Blog-4 | 新一代InfLLM:可训练的稀疏注意力机制MiniCPM4 创新性地引入了 InfLLM v2,一种 可训练的稀疏注意力机制,极大程度降低了计算开销,并结合定制化推理算子 CPM.cu,MiniCPM4 在 预填充 和 解码 阶段都实现了切实的加速效果。
技术Blog-3 | CPM.cu:轻量且高效的端侧大模型推理框架CPM.cu 是一款基于 CUDA 构建的高效大模型推理框架,它集成了稀疏注意力、投机采样与模型量化等多种加速策略,并支持将它们复合使用以实现更极致的推理性能,框架十分轻量且易读。
高效大模型 就是面壁智能高效,源于对大模型科学化的不懈追求以知识密度为核心的「面壁定律」,指引我们进行更高效的大模型科学化探索。在ScalingLaw之外,探索出前瞻、独特的大模型方法论。
围绕提升大模型知识密度这一本质,面壁通过数据、模型的架构以及相关成长算法方面的探索,做到同等参数、性能更强,持续提升大模型制程,将更小更强更高效的模型放到端侧,放到离用户最近的地方!
面壁定律摩尔定律
模型能⼒密度随时间呈指数级增强,达到特定智能水平的模型参数量每 3.3 个月 下降⼀半。基线模型(如 MiniCPM)为实现目标性能所需的参数数量与实际参数数量的比值。
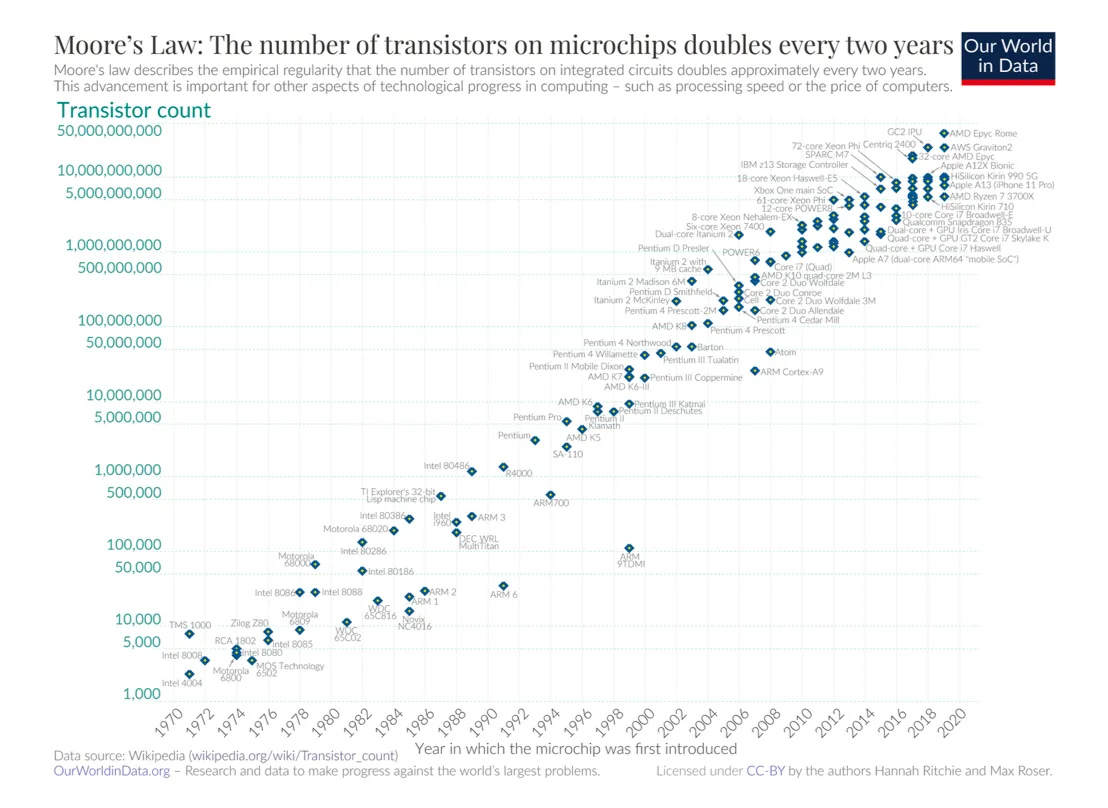
芯片电路密度每18个月提高1倍集成电路上可容纳的晶体管数目 约每隔两年增加一倍
面壁动态





























FlagOS助力 MiniCPM5 在9款芯片(含ARM)适配,Day0实现从云到端生态覆盖,效率追平NVIDIA原生5 月 25 日,面壁智能正式发布并开源了新一代端侧文本基座大模型 MiniCPM5-1B。该模型以 1B 参数规模在 AA-Index 榜单取得 17.9 分,超越 Qwen3.5-2B(16.3 分)等全部 4B 以下开源基座模型,延续了面壁智能提出的"密度定律"——大模型智能密度约每 3.5 个月翻一番。其 Ba
对话刘知远:中国AI要向外卷,而不只是做第二个OpenAI有人继续卷规模,有人转向 Agent,有人下注世界模型。但刘知远和他的团队思考的是另一个问题:AI 为什么一定只能发生在云端? 4 月下旬,DeepSeek-V4 发布后,相对于 V3,行业的反应相对平淡。你怎么看待 V4 这个模型?
AI 制造 AI:面壁智能发布并开源全球首个完全由 AI 编写的生产级训练框架 ForgeTrainAI 能不能写出真正生产级的大型软件,乃至于大模型训练框架? 为什么必须「AI 制造 AI」? 我们开源的不只是代码,更是方法论。从 MiniCPM 系列的端侧高效模型,到今天的 ForgeTrain 和 Forge Engineering
超炫「桌宠」、2B 以下全球最优、开放数据集……MiniCPM5-1B 正式发布并开源!在权威榜单 Artificial Analysis(AA)上,MiniCPM5-1B 的得分(17.9分)位于「小尺寸模型」榜单第一,甚至超过 Qwen3.5-2B(16.3分),成为全球 2B 参数规模以内的最强开源基座模型!
面壁智能联合清华正式开源中国首个基于昇腾训练的 1.58-bit 端侧大模型 BitCPM-CANN为什么我们要在 1.58-bit / 2-bit 这条看起来极端的路线上持续投入?
新一代「小钢炮」来袭!1.3B 模型性能效率双杀,MiniCPM-V 4.6 正式开源让 AI 的智能真正触达每一块屏幕、每一个终端,是我们的愿景,也是我们的使命。欢迎每一位开发者,与我们共同探索端侧 AI 的无限可能!
《智能座舱:定义AGI时代的汽车新范式》白皮书发布白皮书开篇即提出了一个尖锐的问题:智能座舱在中国市场的配装率已突破 76%,但用户真正感知到的智能体验仍然有限。屏幕更大了、功能更多了,为什么很多车主的日常交互仍然停留在"打开某个功能","说出某条标准指令"的层面?
一人公司的新标配:端云协同的“超级数字员工”越来越多的人不再满足于出卖时间的自由职业,而是开始借助 AI 杠杆,把自己活成了一支能持续盈利的队伍。但伴随实践深入,一个更底层的问题开始被更多人关注到:支撑一人企业运转的 AI 基础设施,应该是什么样的?
当《哆啦A梦》开始讲四川话,人人都能当配音师的时代来了如果声音可以更改,你最想改变什么?
语言,声调,音色,情绪,甚至全凭想象,「无中生有」创造一个世界上完全不存在的声音……这是可能实现的目标吗?
面壁智能 EdgeClaw Box 正式发布:给 OpenClaw 装上「安全大脑」和「省钱开关」OPC 时代的数字化基础设施,现已就绪。欢迎开发者与行业伙伴,来面壁智能一起「养虾」!
喜报!面壁智能 3️⃣大成果刷屏!这两天 Hugging Face Trending 太热闹了 —— 面壁智能开源成果一口气占据 3 席!
MiniCPM-o 4.5开源:「眼耳口」并用,模型交互从「一问一答」变为「即时自由对话」沿袭面壁小钢炮一贯的“高密度”特点,MiniCPM-o 4.5 仅靠 9B 参数,在全模态、视觉理解、文档解析、语音理解和生成、声音克隆等方方面面,均做到了全模态模型 SOTA 水准!
坐标已发射,请回答丨面壁急招面壁计划加速,核心技术岗位全线急招。官号专属通道现已开启!
DeepResearch 终于本地化了!8B端侧写作智能体AgentCPM-Report开源!在深度研究(DeepResearch)席卷而来的今天,我们都渴望拥有一位可以综合复杂信息、自动撰写万字长文的个人专属“超级写作助手”。但当你手握公司明年的战略规划、未公开的财务报表,或是涉及核心机密的科研数据时,你真的敢把它们上传到云端吗?
北京人工智能创新高地建设推进会举行,面壁披露端侧智能最新成果1 月 5 日,2026 北京·人工智能创新高地建设推进会在京举行。会上集中发布了《北京人工智能创新高地建设行动计划》、首批北京人工智能创新街区、北京人工智能前沿成果等多项内容,全面呈现了北京在人工智能领域的硬核科技实力与全栈产业生态。大会由北京市发展和改革委员会、北京市科委中关村管委会、北京市经济和信息化局、海淀区人民政府主办。
面壁智能共建「端侧智能北京市重点实验室」近日,北京市科学技术委员会、中关村科技园区管理委员会正式公布 2025 年「北京市重点实验室」名单。以清华大学为依托单位,面壁智能、趋境科技为共建单位的「端侧智能北京市重点实验室」成功获批成立,实验室主任由清华大学计算机系长聘副教授刘知远担任。
进击 2025,你好 2026!2025 年,大模型如浪潮奔涌,从“洞悉万象”,迈向“重塑千行”。岁末回望,这是面壁在潮涌的同频中,踏准节奏、进击前行的一年。我们相信,对本质问题的求索,对长期价值的笃信,是写给未来最坚实的注解。
大模型国内首家!面壁通过ASPICE L2 车规级国际评估面壁智能自主研发「端侧芯算融合大模型」项目,近日正式通过 Automotive SPICE(简称ASPICE)L2 级评估。这标志着面壁在软件开发过程管理、质量控制及工程化交付能力上,已全面对标国际汽车工业标准,并由此成为国内首家通过该项车规级评估的大模型企业。
面壁智能完成数亿元融资,加码投入领跑端侧 AI面壁智能顺利完成本轮融资,得益于端侧智能市场空间进一步打开,更有赖于投资方对面壁的技术实力、市场地位及行业前景的充分认可。作为国内在端侧智能领域布局最早的大模型厂商,面壁构建起完善的理论体系与模型产品谱系,MiniCPM 面壁小钢炮端侧模型已在汽车、手机、PC 及智能家居等多个领域实现规模化落地,与吉利、长安、大众、华为等多家知名企业达成深度合作,端侧大模型的商业化进程走在行业前列。
面壁智能蝉联VENTURE50「人工智能50」榜单12月4日,2025 VENTURE 50 正式揭晓。面壁智能凭借在人工智能领域的创新实践与快速成长,入选「人工智能 50」榜单。这是公司继 2024 年登榜后蝉联入选,体现了评选机构对面壁技术实力、商业化落地能力及发展潜力的持续关注与认可。
面壁智能入选北京市智慧城市创新成果合作伙伴11 月 24 日,2025 北京市智慧城市场景创新发布暨数智北京创新中心生态共建系列活动在京举办。活动由北京市政务服务和数据管理局,北京市科学技术委员会、中关村科技园区管理委员会,北京市教育委员会,石景山区人民政府,通州区人民政府,大兴区人民政府联合主办。面壁智能凭借与北京市司法局联合研发全国首个「行政复议垂直大模型」场景应用,入选「北京市智慧城市场景创新成果合作伙伴(第三批)」。
密度定律登《Nature》子刊封面,大模型「高效」路径获学术认可国际顶级学术期刊《Nature》旗下子刊《Nature Machine Intelligence》近日以封面文章形式,刊发了清华大学与面壁智能的联合研究成果《Densing Law of LLMs》。该研究提出以能力密度作为评估大语言模型效能的关键指标,并揭示其最大能力密度每 3.5 个月翻倍的增长规律,为行业探索科学化、可持续的大模型发展路径提供了参考依据。
面壁受邀参加第28届京港洽谈会,共商科技合作与国际化11 月 12 日,第 28 届北京·香港经济合作研讨洽谈会在香港会展中心举行。大会以「京港携手 联通世界」为主题,设置开幕式、主题推介、13 场专题推介及投资洽谈等环节,邀请来自京港两地的政府机构、国际商协会、领军企业和工商界知名人士逾 800 人参会。面壁智能作为北京市人工智能企业代表,受邀参加开幕式和科技专题活动。
面壁基于第五代骁龙 8 至尊版发布创新端侧智能体 AgentCPM9 月 25 日,2025 高通骁龙峰会·中国期间,面壁智能宣布发布全新 GUI Agent 智能体 AgentCPM,基于面壁 MiniCPM-4V 多模态大模型并面向搭载高通技术公司全新第五代骁龙 8 至尊版移动平台的终端进行优化,带来 AgentCPM(4B)中英文版本,能够完全在终端侧运行,结合用户需求自动化完成复杂任务,带来更具个性化的终端侧智能体AI体验。
“小钢炮”端侧 VLA 大模型上车!面壁助力吉利银河 M9 打造全新人机交互「AI 科技大六座旗舰 SUV」吉利银河 M9 近日全球上市发布。作为吉利打造的全能旗舰标杆,银河 M9 融合「AI 智能座舱、AI 数字底盘、AI 辅助驾驶」三大 AI 科技,为车主与乘客提供全场景的智慧出行体验。
VoxCPM 登顶 HuggingFace TOP1面壁小钢炮首款语音生成模型 VoxCPM 一经发布,广受好评,成功登顶 HuggingFace TOP1。
面壁与辉羲达成战略合作 加速汽车、具身智能等端侧AI创新9 月 19 日,面壁智能与辉羲智能正式签署战略合作协议,双方将结合各自在大模型算法与 AI 芯片领域的核心优势,共同推进端侧 AI 技术的创新与应用落地,加速高效能 AI 在多元终端场景的规模化普及。
全文速递|刘知远分享《大模型智能体发展的关键技术与挑战》在日前举行的上海外滩大会上,清华大学计算机系长聘副教授、面壁智能联合创始人兼首席科学家刘知远发表主题演讲,分享大模型智能体发展的关键技术与挑战。
面壁智能上榜《麻省理工科技评论》“50家聪明公司”9 月 12 日,全球知名技术商业类杂志《麻省理工科技评论》(MIT Technology Review)发布新一届「50 家聪明公司(TR50)」榜单,面壁智能成功入选。《麻省理工科技评论》给出的上榜理由为:面壁智能使终端设备本地运行大模型成为可能。
2025服贸会特设「北京方案展」,全国首个行政复议大模型亮相9 月 10 日至 14 日,由商务部、北京市政府共同主办的2025年中国国际服务贸易交易会在北京首钢园区举办。「北京方案展」作为本届服贸会的核心亮点之一同期展陈,旨在展示北京全球数字经济标杆城市建设成果,推动优秀数字服务北京方案走向全国,迈向国际。
MiniCPM-V 4.5 登上 HuggingFace TOP2面壁最新诚意之作 MiniCPM-V 4.5,8B 小身材爆发超高性能,高刷视频理解被称为「鹰眼级」,一经开源,就收获了开发者的热情回应,登上 HuggingFace Trending TOP2。
面壁CTO曾国洋上榜《财富》“中国40岁以下最具潜力的商界精英”8 月 12 日,《财富》(中文版)发布 2025 年“中国 40 岁以下最具潜力的商界精英”榜单。面壁智能 CTO 曾国洋上榜,成为榜单上最年轻的人工智能领域代表人物。
李大海出席全球数字经济大会: 2025 开启端侧智能元年7 月 3 日,2025 全球数字经济大会·人工智能融合应用发展论坛在北京国家会议中心举办。论坛以“大模型·深应用·强产业”为主题,突出“应用落地、场景驱动”的特色。面壁智能 CEO 李大海应邀出席论坛并发表演讲。他提出:“2025 年应用爆发式发展,开启了端侧智能的元年。面壁将始终坚守‘高效’的第一性原理,强化‘终端大脑’的智能化水平与商业化落地,推动智能的平权普惠早日实现。”
面壁“小钢炮”登上 Nature 子刊,端侧多模态能力获学术顶级认可7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了面壁「小钢炮」MiniCPM-V 核心研究成果。值得一提的是,这是《Nature》系列期刊第二次刊登面壁智能相关研究成果。MiniCPM-V 是由面壁智能、OpenBMB 团队联合研发的端侧多模态模型,仅依靠 8B 参数实现了多模态综合性能超越 GPT-4V、Gemini Pro 等万亿参数云端模型,并首次在手机、平板、汽车等算力受限的终端设备上实现实时推理的重大突破,也标志着以面壁智能为代表的中国高效大模型技术创新成果获得国际学术界充分认可。
面壁“小钢炮”登上 Nature 子刊,端侧多模态能力获学术顶级认可7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了面壁「小钢炮」MiniCPM-V 核心研究成果。值得一提的是,这是《Nature》系列期刊第二次刊登面壁智能相关研究成果。MiniCPM-V 是由面壁智能、OpenBMB 团队联合研发的端侧多模态模型,仅依靠 8B 参数实现了多模态综合性能超越 GPT-4V、Gemini Pro 等万亿参数云端模型,并首次在手机、平板、汽车等算力受限的终端设备上实现实时推理的重大突破,也标志着以面壁智能为代表的中国高效大模型技术创新成果获得国际学术界充分认可。
面壁MiniCPM 4与Intel全面适配 实现AI PC 2.2倍长文本推理优化英特尔与面壁智能从模型开发阶段就紧密合作,实现了长短文本多重推理效率的提升,端侧 AI PC 在 Day 0 全面适配,128K 长上下文窗口等多方面突破。
端侧智能家居革命!面壁智能与易来联合发布行业首款纯端侧AI家居中枢2025 年 6 月 4 日,端侧大模型领军企业面壁智能与国内智能照明领导品牌易来(Yeelight)正式签署战略合作协议,并联合发布了 Yeelight Pro S 系列 AI 智慧屏。作为家居行业首款本地部署 AI 大语言模型的全能控制终端,Yeelight Pro S 集成了面壁智能端侧「小钢炮」 MiniCPM 模型,首次实现家居设备的全本地化 AI 交互、控制,标志着智能家居行业从 “云端依赖” 向 “端侧自主” 的重大跃迁,为用户带来更加智能、安全的家居新体验。
面壁智能获新一轮数亿元融资,引领端侧大模型高效发展与应用普及近日,面壁智能完成新一轮数亿元融资,本轮融资由洪泰基金、国中资本、清控金信和茅台基金联合投资。本轮融资的完成,将进一步为面壁智能构筑高效大模型技术、产品壁垒、加速行业赋能与生态拓展奠定坚实基础,协同产业上下游推动「端侧大脑」在千行百业规模化应用。
ChatDev 2.0:零代码构建多智能体,快速开发一切还记得之前被吴恩达强烈推荐、连续 7 天霸榜 GitHub Trending 榜首、收获 28k Star 及 3300 次分支复刻、首次将大模型智能体协作模式赋能于自主任务解决的多智能体框架 ChatDev (Chat-powered S
面壁智能联合德赛西威发布业界首款高通8255平台端侧大模型语音方案,引领车载语音交互新范式端侧大模型技术领军企业面壁智能与全球领先的移动出行科技公司德赛西威共同发布业界首个基于高通座舱平台(SA8255P,简称8255)的端侧大模型语音交互方案,这是双方自 2024 年 12 月签署战略合作协议以来发布的首个合作成果。
科创之光闪耀!面壁智能CEO李大海出席2025北京大学校友科技创新论坛2025 年 5 月 3 日,“2025 北京大学校友科技创新论坛”在北京大学秋林报告厅圆满举行,面壁智能 CEO 李大海与全球顶尖科学家、企业家、创业者与优秀校友代表 300 余人共同出席论坛。本次论坛以“未名同行,智启未来”为主题,共同聚焦前沿技术趋势与产业转化路径,展现科技领域创新创业最新成果,发出科创时代北大之声。
广西壮族自治区领导会见面壁智能负责人刘知远、李大海5 月 7 日,广西壮族自治区党委书记、自治区人大常委会主任陈刚,在南宁会见北京面壁智能科技有限责任公司联合创始人刘知远、李大海。
小钢炮风暴,燃爆 2025 上海车展端侧大模型,汽车加速度!
中科创达与面壁智能达成战略合作,基于滴水OS打造下一代智能座舱新体验2025 年 4 月 24 日,人工智能大模型端侧模型世界知名创企面壁智能与全球领先的智能操作系统及端侧智能产品和技术提供商中科创达达成战略合作,双方将深度整合优势资源,共同打造下一代 AI 座舱交互新体验。面壁智能联合创始人、首席执行官(CEO)李大海、联合创始人、首席运营官(COO)雷升涛、中科创达联合创始人兼执行总裁耿增强、智能汽车事业群副总裁兼滴水智行总经理宋洋及双方相关人员出席了本次签约仪式。
英特尔与面壁智能宣布建立战略合作伙伴关系,共同研发端侧原生智能座舱,定义下一代车载AI2025 年 4 月 24 日,上海 ——英特尔与面壁智能签署合作备忘录。双方宣布达成战略级合作伙伴关系,旨在打造 端侧原生智能座舱,定义下一代车载 AI。目前,双方已合作 “英特尔&面壁智能车载大模型 GUI 智能体”,将端侧AI大模型引入汽车座舱,让用户不再受限于网络环境,随时随地享受便捷、智能的座舱体验。
北京市委书记尹力、市长殷勇调研走访面壁智能4 月 7 日下午,市委书记尹力围绕“加快建设北京国际科技创新中心,培育壮大人工智能产业”到海淀区调查研究。他强调,人工智能是引领这一轮科技革命和产业变革的战略性技术,具有溢出带动性很强的“头雁”效应。要深刻认识加快发展人工智能的战略意义,充分发挥首都教育科技人才优势,坚持创新与应用并重,努力打造具有全球影响力的人工智能创新策源地和产业高地,为国家赢得国际科技竞争主动权贡献北京力量。市委副书记、市长殷勇,市委副书记、组织部部长游钧一同调研。
面壁智能CTO曾国洋入选《麻省理工科技评论》中国“AI100青年先锋”3月29日,面壁智能 CTO 曾国洋入选《麻省理工科技评论》中国与 DeepTech 联合发布的“AI100青年先锋”榜单。该评选聚焦40岁以下中国 AI 领军人才,从技术创新、产业落地及社会价值等维度遴选出推动行业变革的中坚力量。
“大模型上车”技术爆发,面壁智能打造超性能「端侧大脑」接管智能座舱!3月30日,面壁智能 CEO 李大海出席 2025 中国电动汽车百人会,并发表主题演讲。他宣布面壁将进军智能座舱领域,推进智能汽车「端侧大脑」开发。以行业首个纯端侧智能助手cpmGO(小钢炮超级助手)为起点,面壁智能正致力于构建车端最强「端侧大脑」,推动智能汽车产品跨越式提升,为用户带来更高阶、更智能的体验。
面壁智能入选2025中关村论坛10项重大科技成果发布2025 年 3 月 27 日,中关村论坛年会开幕式暨全体会议正式举行,面壁智能MiniCPM 端侧模型作为开源系列成果代表案例之一,成功入选「10 项重大科技成果」,并在论坛现场进行重磅发布。MiniCPM 正以一系列前沿创新引领全球端侧模型技术发展。
海淀区委书记张革一行莅临面壁智能调研3月6日,北京市海淀区委书记张革围绕“充分发挥企业创新主体作用,促进民营经济健康发展、高质量发展”主题,到面壁智能开展调研,区领导齐慧超、唐超、赵寒一同参加调研,面壁智能联合创始人刘知远、雷升涛等接待来访并进行座谈。
5 城任选|面壁邀你加入「执剑计划」,一起引爆端侧 AI 革命让我们一起,把大模型放到离用户最近的地方!
VoxCPM 登上 HuggingFace TOP2点这里快速回顾 VoxCPM :面壁小钢炮迎新:VoxCPM 语音生成媲美真人、声音复刻超像!
面壁小钢炮迎新:VoxCPM 语音生成媲美真人、声音复刻超像!> We've traveled too far and sacrificed too much to turn back now. This is our last stand. Whatever happens here today,
面壁小钢炮更强了!“端侧大脑”亮相 WAIC 2025WAIC 2026,再会!
WAIC 2025:刘知远谈大模型演进趋势与端侧智能端侧模型和端侧芯片是 AI 变革过程中衍生出的比较新的赛道,目前有什么突破性进展? 端侧模型的下一个技术拐点预计在什么时候到来?为此面壁做了哪些准备和计划?
最高220倍加速!面壁小钢炮4.0,稀疏创新黑科技大爆发有史以来最具想象力的小钢炮系列,MiniCPM 4.0 来了! 引入稀疏注意力架构,做从内而外的创新,为什么在当下如此重要? 在传统 Tansformer 模型的相关性计算中,每个 token 都需要和序列中所有 token 进行相关性计算
首个端侧模型量产车型问世!面壁携手车企伙伴打造车载智能标杆“大模型上车”技术爆发,面壁智能打造超性能「端侧大脑」接管智能座舱!
“大模型上车”技术爆发,面壁智能打造超性能「端侧大脑」接管智能座舱!李大海指出:超性能、全场景、纯端侧大模型驱动的智能座舱,是行业新技术方向。面壁小钢炮 MiniCPM 上车,纯端侧方案功能与云端大模型全面对齐,但长板更长! 为什么在云端大模型之外,智能座舱还需要一个超性能、纯端侧方案?
面壁发布首个纯端侧智能助手,构建汽车超性能端侧大脑这一刻的到来,仍有许多工作亟待解决。面壁团队和面壁小钢炮端侧模型,将以 AGI 为最终愿景,不懈努力,攻坚克难,将极致的大模型智能体验放到离每个用户最近的地方!
小钢炮上车,构建汽车机器人「端侧大脑」!电动汽车百人会见倒计时 2 天,一起探索以面壁小钢炮指挥的「汽车端侧大脑」!
这周六,和小钢炮一起出发!周六下午,面壁智能 CEO 李大海将出席未来人工智能先锋论坛,汇报面壁小钢炮的最新进展,欢迎大家来「中关村国际创新中心-畅春厅」找我们玩!
面壁智能首次参展CES,小钢炮出海瞄准更广阔市场面壁智能携 MiniCPM 系列端侧模型亮相 CES 2025,全方位展示 MiniCPM 文本模型和多模态模型的关键特性,以及落地 PC、智能座舱、具身机器人等领域的重要成果和突破。
好消息!O 系小钢炮一经发布,4 天霸榜!MiniCPM-o 2.6 一经开源,连续霸榜 GitHub Trending 榜单 4 天! 端侧GPT-4o来了!全新面壁小钢炮,流式全模态+端到端! 为前来体验的开发者朋友们端上新鲜出炉的部署教程,若有更多精彩案例,也欢迎一起共建!
面壁智能与追知工科达成战略合作,合作开发工业AI垂域模型日前,北京面壁智能科技有限公司(以下简称“面壁智能”)与上海追知工程科技有限公司(以下简称“追知工科”)举行战略合作签约仪式。
法制日报采访刘知远等研发代表:法律基座大模型将带来哪些“智体验”?今年 11 月,最高人民法院发布了“法信法律基座大模型”(以下简称大模型)。这是最高法积极探索使用人工智能技术为司法赋能,推动人工智能与司法工作深度融合的重要成果。定位于国内法治领域“行业基座”大模型,它是如何“学习”法学知识和司法审判业务的?在积极拥抱科技的同时,如何确保大模型可靠可控?未来大模型将给法律行业带来怎样的“智体验”?《法治日报》记者就此采访了大模型合作研发团队负责人和有关专家。
面壁小钢炮,推动端侧 AI 生态建设进行时面壁智能 CTO 曾国洋出席安谋科技(Arm China)主办的「AI 启终端,创‘芯’领航」端侧 AI 生态研讨会,并发表《摩尔定律和面壁定律交汇 MiniCPM 赋能新一代旗舰移动 SoC》主题演讲。
谁是 2024 大模型人气王?在 Hugging Face 「2024 最受欢迎最多下载榜单」中,面壁小钢炮系列 MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.6 双双上榜,并在全球明星大模型版图中占比 2.7%,位列中国模型 TOP1 !
面壁智能 CTO 曾国洋荣登 2024 胡润 U25 中国创业先锋近日,面壁智能联合创始人、CTO 曾国洋荣登《2024 胡润 U25 中国创业先锋》(Hurun China Under25s 2024),该榜单来自全球最大的创业企业榜单编制机构胡润研究院。
面壁智能获新一轮数亿元融资,高效端侧智能持续引领行业发展近日,面壁智能完成新一轮数亿元融资,本轮融资由龙芯创投、鼎晖百孚、中关村科学城基金和赛富投资基金联合领投,北京市人工智能产业投资基金与清科创投跟投,万甲资本担任本轮独家财务顾问。
面壁智能携手英特尔打造高效AIPC,MiniCPM端侧模型正获巨大市场推动和技术加速11 月 26 日,英特尔新质生产力技术生态大会(Intel Connection)在成都举办,面壁智能作为英特尔重要战略合作伙伴出席,并演示了基于英特尔最新一代桌面级旗舰芯片深度适配和加速的多模态端侧模型。
Vol 6. Newsletter | 面壁月度精选11月19日,2024 年“携手构建网络空间命运共同体精品案例”发布展示活动在浙江乌镇举办。「面向网络空间开源开放的多模态大模型 MiniCPM-V」成功入选。MiniCPM-V 多模态大模型由面壁智能联合清华大学、新加坡国立大学共同研发
面壁智能CTO曾国洋入选2024年度“北京市科技新星计划”北京市科学技术委员会、中关村科技园区管理委员会公布了 2024 年“北京市科技新星计划”拟入选人员名单,面壁智能 CTO 曾国洋入选“北京市科技新星计划”创业新星项目。
面壁智能联手大象机器人,带来超级仿真、情感细腻的机器萌宠云端大模型和端侧模型,有一些微妙的价值差异。端侧模型离用户最近,它能快速落地,进入千家万户还伴随着足够强的产品差异化,这也是终端厂商梦寐以求的大模型:经过端侧模型的改造加持,足够凸显原创和异于同品类的体验差异。
面壁智能牵手加速进化机器人,打造端侧模型与具身机器人融合先驱2024 世界机器人大会期间,面壁智能联手加速进化机器人(Booster Robotics),打造出完整“具身智能”的先驱方案,业界首个高效端侧模型运行在人形机器人的演示,理解、推理、并与物理世界互动的智能系统,这激动人心的未来场景,已拉开帷幕!
面壁智能受邀出席《财富》人工智能主题大会大模型是全球瞩目的热门领域,端侧 AI 亦被认为是行业发展下一转折趋势。近日,面壁智能作为中国大模型企业代表,受邀出席正在新加坡举办的 2024《财富》(Fortune)人工智能主题大会。
百度智能云x面壁智能,共同打造大模型端云协同新范式10月30日,面壁智能与百度智能云举行战略合作签约仪式,双方将共同打造大模型端云协同解决方案,共同推动大模型技术加速落地具身智能、智能终端、边缘计算等行业应用。面壁智能联合创始人、CEO李大海,面壁智能COO雷升涛,百度智能云泛科技业务部总经理张玮及双方相关人员出席了本次签约。
面壁智能刘知远:5G-A 与 AI 融合将迎来新发展浪潮随着5G-A商用与入端元年的到来,为社会工作与生活带来了巨大的变化。近日,清华大学副教授、面壁智能联合创始人兼首席科学家刘知远在接受记者采访时表示,“5G-A与AI的融合发展,目前还处于刚刚起步的阶段,未来将会迎来非常大的发展浪潮。”
面壁与MediaTek联合优化新一代移动SoC 芯片10月16日消息,近日,MeidaTek发布新一代3nm制程移动SoC天玑9400,这是面壁智能与MediaTek达成正式合作,联合调校新一代移动SoC 端侧AI能力的全新旗舰芯片。
筑垒加码!长城汽车与面壁智能签署战略合作协议9月27日,长城汽车与面壁智能签署战略合作协议,双方将就大模型技术的研发应用在汽车领域展开深入合作。双方此次合作,旨在围绕长城汽车的AI大模型技术与数据积累,以面壁智能在端侧大模型的研发与应用的全栈能力,与长城汽车多个技术栈进行产品融合、创新,加快长城汽车大模型技术在汽车领域的落地,为长城汽车智慧出行与用户服务的发展提供新的技术动力。
Vol4. Newsletter | 面壁月度精选八月大事记:
💥 发布面壁「小钢炮」 MiniCPM-V 2.6
🎯 小钢炮 2.6 GitHub万星成就达成,登顶GitHub Trending,跻身HuggingFace Trending Top3
🎂 面壁智能两周岁,探索新征程,召唤「新同类」
👯♀️ OpenBMB开源社区开启首批小钢炮挚友计划
🥰 社区活动 · 面壁小钢炮七夕线下品鉴会
👍 面壁智能联合创始人、首席科学家刘知远在世界机器人大会发表演讲
🤩 面壁智能受邀出席《财富》人工智能主题大会
🤝 牵手「加速进化机器人」,打造完整“具身智能”的先驱方案
🐘 与大象机器人达成正式合作
Vol3. Newsletter | 面壁月度精选六七月大事记:
🎯 面壁「小钢炮」 MiniCPM 下载量突破100万
🤖 发布智能体互联网(IoA)
👩🏫 OpenBMB经典大模型课第二季正式上线
🏆 「你好!面壁小钢炮」系列技术教程上线
🤝 与华为连续深化合作,共筑大模型生态
👍 助力全国首个司法审判垂直领域大模型落地,获央视点赞
🔥 携创新之作亮相 WAIC 2024,拉开端侧AI生态序幕
🏅 入选北京市通用人工智能产业创新伙伴计划第三批成员单位
✨ 亮相智源大会,与顶尖大模型公司掌门人共话AGI
📆 面壁学术沙龙第四到六期成功举办
🆓 面壁「小钢炮」 MiniCPM 免费商用
Vol1. Newsletter | 面壁月度精选五月大事记:
🤖 开源大模型「理科状元」Eurux-8x22B 发布
👍 GPT-4V级最强端侧多模态模型发布
📆 面壁学术沙龙第二、三期成功举办
🔎 面壁研究员参加 ICLR 2024学术会议
👀 昇腾开发者大会:面壁智能 CTO 曾国洋发表演讲
💌 5月20日,写给开源社区的情书
🤝 面壁「小钢炮」MiniCPM 在 NAS 行业落地
刘知远做客《人民会客厅》高端访谈,展望AI“入端”的未来机遇面壁联合创始人、首席科学家刘知远做客人民网出品的权威高端访谈栏目《人民会客厅》,与华为公司副总裁、无线网络产品线总裁曹明,TD 产业联盟秘书长杨骅,中国移动首席专家王大鹏一道,共同探讨在移动AI时代下,如何把握 5G-A 与 AI 融合的潮流,迎接更加智能、便捷的未来。
面壁智能出席 2024 百度云智大会9月25日,以“智能·跃迁”为主题的 2024 百度云智大会在北京举办。作为端侧大模型与具身机器人融合方案的先驱,面壁智能受邀出席大会具身智能专题论坛,面壁智能联合创始人、CTO曾国洋与多位嘉宾一道齐齐亮相,并作了端侧模型赋能具身智能行业的精彩分享。
李大海对话脉脉创始人林凡,畅谈端侧模型最新趋势9 月 24 日,面壁智能创始人兼 CEO 李大海坐客《Fan谈大模型》节目直播间,与脉脉创始人兼 CEO 林凡展开「iPhone 16 来了,真正的 AI手 机离我们还有多远?」的精彩对话,围绕端侧大模型、终端结合趋势、AI+个人成长、AI+职业规划、AI+未来企业组织形态等话题,带来了深入一线的宝贵洞察。
2024世界机器人大会,刘知远最新演讲:大模型、知识密度定律与端侧智能8 月 21 日下午,2024 世界机器人大会 (WRC)「大模型技术赋能机器人产业新范式论坛」正式举行,面壁智能联合创始人、首席科学家刘知远受邀出席并发表《大模型、知识密度定律与端侧智能》主题演讲。
面壁智能与百度智能云达成战略合作,共赴大模型端云协同应用蓝海10 月 30 日,面壁智能与百度智能云举行战略合作签约仪式,双方将共同打造大模型端云协同解决方案,共同推动大模型技术加速落地具身智能、智能终端、边缘计算等行业应用。面壁智能联合创始人、CEO李大海,面壁智能 COO 雷升涛,百度智能云泛科技业务部总经理张玮及双方相关人员出席了本次签约。
面壁联合英特尔深度调校最新一代桌面级旗舰芯片,MiniCPM落地AIPC性能将获跨越式提升10 月 25 日,英特尔酷睿 Ultra 处理器(第二代)品鉴会暨以“强大的 不止 AI ”为主题的 AI PC 生态大会在北京举办,作为英特尔 AI PC 产业生态的重要合作伙伴,面壁智能携手英特尔深度优化采用最新一代 x86 平台的酷睿 Ultra 200S(Arrow Lake)的端侧模型部署和计算加速,在英特尔酷睿 Ultra 处理器和 OpenVINO 工具套件的帮助下,面壁 MiniCPM 端侧模型的 PC 端应用性能得到跨越式提升。
端侧模型芯片级调优!面壁与MediaTek联合优化新一代移动SoC芯片,多模态端侧AI将成高端“标配”10 月 9 日,MediaTek 发布新一代 3nm 先进制程移动 SoC 天玑 9400 芯片,这是面壁智能与 MediaTek 达成正式合作、联合调校新一代移动 SoC 端侧 AI 能力的全新旗舰芯片,突破了以往移动 SoC 流畅运行端侧多模态模型的诸多关键瓶颈。
面壁智能与长城汽车签署战略合作协议9月27日,面壁智能与长城汽车签署战略合作协议,双方将就大模型技术的研发应用在汽车领域展开深入合作。双方此次合作,面壁智能将充分释放端侧大模型的研发与应用的全栈能力,结合长城汽车的AI大模型技术与数据积累,让世界前沿的大模型技术与长城汽车多个技术栈进行产品融合、创新,赋能长城汽车的场景和应用突破,为长城汽车智慧出行与用户服务的发展提供新的技术动力。
双登顶!面壁小钢炮3.0 GitHub Top 1,Hugging Face Top 3面壁小钢炮 MiniCPM 3.0 持续引领端侧 ChatGPT 时代!
端侧 ChatGPT 时刻到来!面壁小钢炮 3.0 重磅发布面壁发布小钢炮3.0
星标破万!小钢炮2.6登顶GitHub,Hugging Face TOP3, 燃爆开源社区!想到了直升机,没想到的是火箭! MiniCPM-V 2.6 一经发布,火箭登顶全球著名开源社区 GitHub 与 HuggingFace 趋势榜 Top 3。 至此,面壁小钢炮 MiniCPM-V系列,GitHub 星标破万! 小钢炮MiniCPM系列自今年2月1日面世以来,累计下载量已超百万!
多图、视频首上端!3 SOTA 面壁小钢炮,创 GPT-4V 端侧全面对标新时代!再次刷新端侧多模态天花板,面壁「小钢炮」 MiniCPM-V 2.6 模型重磅上新!
仅 8B 参数,取得 20B 以下单图、多图、视频理解 3 SOTA 成绩,一举将端侧AI多模态能力拉升至全面对标 GPT-4V 水平。
更有多项功能首次上「端」:小钢炮一口气将实时视频理解、多图联合理解、多图 ICL 等能力首次搬上端侧多模态模型,更接近充斥着复杂、模糊、连续实时视觉信息的多模态真实世界,更能充分发挥端侧 AI 传感器富集、贴近用户的优势。
面壁智能与百度智能云达成战略合作,共赴大模型端云协同应用蓝海10 月 30 日,面壁智能与百度智能云举行战略合作签约仪式,双方将共同打造大模型端云协同解决方案,共同推动大模型技术加速落地具身智能、智能终端、边缘计算等行业应用。面壁智能联合创始人、CEO李大海,面壁智能 COO 雷升涛,百度智能云泛科技业务部总经理张玮及双方相关人员出席了本次签约。
面壁联合英特尔深度调校最新一代桌面级旗舰芯片,MiniCPM落地AIPC性能将获跨越式提升10 月 25 日,英特尔酷睿 Ultra 处理器(第二代)品鉴会暨以“强大的 不止 AI ”为主题的 AI PC 生态大会在北京举办,作为英特尔 AI PC 产业生态的重要合作伙伴,面壁智能携手英特尔深度优化采用最新一代 x86 平台的酷睿 Ultra 200S(Arrow Lake)的端侧模型部署和计算加速,在英特尔酷睿 Ultra 处理器和 OpenVINO 工具套件的帮助下,面壁 MiniCPM 端侧模型的 PC 端应用性能得到跨越式提升。
面壁智能与长城汽车签署战略合作协议9月27日,面壁智能与长城汽车签署战略合作协议,双方将就大模型技术的研发应用在汽车领域展开深入合作。双方此次合作,面壁智能将充分释放端侧大模型的研发与应用的全栈能力,结合长城汽车的AI大模型技术与数据积累,让世界前沿的大模型技术与长城汽车多个技术栈进行产品融合、创新,赋能长城汽车的场景和应用突破,为长城汽车智慧出行与用户服务的发展提供新的技术动力。
Vol 5. Newsletter | 面壁月度精选仅 4B 参数,MiniCPM 3.0 在自然语言理解、知识、代码、数学等多项能力上对GPT-3.5 实现赶超,并越过 Qwen2-7BPhi-3.5,GLM4-9B,LLaMa3-8B 等一众中外知名模型的表现脱颖而出。让 GPT-3.5
面壁联合英特尔深度调校最新一代桌面级旗舰芯片,MiniCPM落地AIPC性能将获跨越式提升面壁智能与英特尔的合作标志着 AI PC 从模型层到终端硬件全面打通。在英特尔卓越的芯片设计和制造赋能下,AI PC 两块“关键拼图”端侧模型与底层算力芯片之间的协调兼容、适配优化和计算加速正跃升到一个全新的水平。高效端侧模型加持下,更安全
面壁智能携手MediaTek,联合调校端侧AI能力祝贺 MediaTek 发布新一代移动旗舰 SoC 天玑 9400,达成了手机芯片流畅运行端侧多模态模型的能力标杆!这也是面壁智能与 MediaTek 联合调校端侧 AI 能力的里程碑!
双登顶!面壁小钢炮3.0 GitHub Top 1,Hugging Face Top 3面壁小钢炮 MiniCPM 3.0 持续引领端侧 ChatGPT 时代!
面壁2岁了,我们要造一艘巨轮,远航!李大海:感谢面壁所有同学,我们是一个有理想、有斗志、了不起的团队! 我们坚持本质思考,闯出了自己的独特路线。大模型爆品级的面壁小钢炮端侧模型,领跑着世界端侧 AI 的发展。2B、2C两端,首个司法审判垂直模型等杰出产品的诞生等,不断刷新行业
面壁智能牵手加速进化机器人,打造端侧模型与具身机器人融合先驱大模型与机器人融合的 “具身智能”,一定是未来三十年最令人期待的科技突破! 2024 世界机器人大会期间,面壁智能联手加速进化机器人(Booster Robotics),打造出完整“具身智能”的先驱方案,业界首个高效端侧模型运行在人形机器人
面壁两岁了,我们寻找面壁计划的「新同类」新征程,呼唤面壁计划的「新同类」,和我们共同探索「大模型科学化」,把更高知识密度、更高效的大模型,放到离用户最近的地方!
星标破万!小钢炮2.6登顶GitHub,Hugging Face TOP3, 燃爆开源社区!想到了直升机,没想到的是火箭! MiniCPM-V 2.6 一经发布,火箭登顶全球著名开源社区 GitHub 与 HuggingFace 趋势榜 Top 3。 至此,面壁小钢炮 MiniCPM-V系列,GitHub 星标破万! 小钢炮Min
多图、视频首上端!3 SOTA 面壁小钢炮,创 GPT-4V 端侧全面对标新时代!再次刷新端侧多模态天花板,面壁「小钢炮」 MiniCPM-V 2.6 模型重磅上新! 2\. 强悍的多图复杂推理能力,竟能读懂你的梗! 给出两组神转折画面,以及对画面中的「梗」给出示意文字描述,例如一个戴着手套、重视卫生的厨师,下一秒却用戴
迈向 IoA 智联网的第一步,面壁将异构智能体“孤岛”连接成完整大陆同样的道理,目前正在快速发展、散落在全球各地的异质Agent智能体连接起来,loA的诞生将在未来产生何种巨大的影响?
WAIC 2024 ,面壁带来哪些新发布?其次,面壁开源了业内首个端侧大模型工具集 "MobileCPM ",帮助开发者一键集成大模型到APP。这意味着什么?
WAIC 2024,面壁打开大模型新定律、新架构、新生态!如下图所示,相比 OpenAI 于2020年发布的1750亿参数的 GPT-3,2024 年初,面壁发布具备 GPT-3 同等性能但参数仅为24亿的 MiniCPM-2.4B ,把知识密度提高了大概 86 倍 !
现场直击WAIC 2024!李大海详解高效大模型,面壁成打卡圣地!热҈热҈热҈ ! WAIC 2024,面壁智能热҈到爆҈炸҈ ! 如果用一个词来形容上海今日的天气,那就是——热热热! 如果用一个词来形容WAIC的面壁智能,那就是——热到爆炸!
面壁助力,全国首个司法审判垂直领域大模型在深圳诞生!全国首个司法审判垂直领域大模型于深圳诞生!
感谢社区厚爱,面壁小钢炮 MiniCPM 免费商用感谢全球开源社区的朋友们,一路厚爱与支持! 全球最主流模型部署框架 Gradio 连发两条推文:庆祝 MiniCPM-Llama3-V 2.5 取得优异成绩,为携手扩展多模态大模型的应用边界而高兴!
Vol1. Newsletter | 面壁月度精选开源是一种信仰,是技术人对这个世界滚烫的热爱! 作为全球开源社区的贡献者和受益者,OpenBMB社区&面壁智能, 在5月20日,给大家送上一枚小钢炮520 特别礼物,我们向全球开源社区的朋友们致以特别问候!
面壁「小钢炮」落地 NAS 行业, 携手极空间推动端侧模型落地面壁「小钢炮」MiniCPM 在 NAS 行业落地啦! 日前发布的 MiniCPM-Llama3-V 2.5 是当前全球最强端侧多模态模型。以仅 8B 的体量,取得了超越多模态巨无霸 Gemini Pro 、GPT-4V 的多模态综合性能
最强端侧多模态模型,Once More!从面壁「小钢炮」三月三级跳的迅猛进化来看,推动推理成本大幅降低、大模型高效落地,胜利在望! 现在,上百个国家的几十亿人口,终于可以自如使用母语和端侧大模型交流,不再游离于前沿科技发展的主线,也因此享有更多AI应用落地、生活品质提升与参与科技
面壁新模型:早于Llama3、比肩 Llama3、推理超越 Llama3!开源大模型「理科状元」Eurux-8x22B在实际应用中表现如何呢? 面壁 Ultra 对齐技术,大模型上分神器! 从领先的端侧模型「小钢炮」MiniCPM,到开源模型推理新 SOTA 的Eurux-8x22B,为什么面壁智能总能推出同等参
面壁智能亮相中关村论坛10项重大科技成果发布未来几天,我们将在中关村论坛带来更多行业分享,敬请期待!
新一代旗舰端侧模型:面壁 MiniCPM 2.0 发布在「高效大模型」的路径下,把大模型变得更小!更强!推动大模型落地应用!
MiniCPM亮相AMD AI PC创新峰会,探索大模型端云协同新场景「2B性能小钢炮」面壁MiniCPM,现已适配 AMD 锐龙 8000 系列AI PC,用户可以在全新的AMD AI PC上快速本地化部署和运行面壁MiniCPM,在保持低成本的同时,显著提高了处理速度和性能,大幅提高PC端生产力!
A G I F O R L I V E S
智 周 万 物